实验目的
掌握R语言对数据集数据质量的分析方法
实验原理
在对数据进行分析和挖掘之前,首先要对数据进行预处理,将数据集中含有的脏数据处理掉,因此,数据质量分析是数据分析和数据挖掘的基础,只有有效的数据才能挖掘出真正的信息。
数据质量分析主要是以数据提供信息的正确性和有效性为目标,本节教程主要介绍缺失值分析和异常值分析。
实验步骤
1、缺失值分析
值分析可以帮助我们从总体上分析数据的自然分布,发现数据集中是否会出现不合常理的数据、缺失值等。
下面使用R语言中VIM包中的sleep数据集作为例子,sleep数据集是一组有关哺乳动物的睡眠数据,含有62个观测、10个变量,利用mice包中的函数对数据集中的缺失值进行分析,首先安装必要的软件包并加载
> install.packages("mice")
> install.packages("VIM")
> library(mice)
> library(VIM)
加载sleep数据集,首先调用summary()函数查看数据基本统计量,可以看出数据集中个变量中缺失值的个数以及分布,其中表格内的1表示没有缺失值,0表示存在确实数据,并在每行和每列的末尾给出了缺失值的统计频数
> data(sleep,package='VIM')
> summary(sleep)
BodyWgt BrainWgt NonD Dream Sleep
Min. : 0.005 Min. : 0.14 Min. : 2.100 Min. :0.000 Min. : 2.60
1st Qu.: 0.600 1st Qu.: 4.25 1st Qu.: 6.250 1st Qu.:0.900 1st Qu.: 8.05
Median : 3.342 Median : 17.25 Median : 8.350 Median :1.800 Median :10.45
Mean : 198.790 Mean : 283.13 Mean : 8.673 Mean :1.972 Mean :10.53
3rd Qu.: 48.203 3rd Qu.: 166.00 3rd Qu.:11.000 3rd Qu.:2.550 3rd Qu.:13.20
Max. :6654.000 Max. :5712.00 Max. :17.900 Max. :6.600 Max. :19.90
NA's :14 NA's :12 NA's :4
Span Gest Pred Exp Danger
Min. : 2.000 Min. : 12.00 Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.: 6.625 1st Qu.: 35.75 1st Qu.:2.000 1st Qu.:1.000 1st Qu.:1.000
Median : 15.100 Median : 79.00 Median :3.000 Median :2.000 Median :2.000
Mean : 19.878 Mean :142.35 Mean :2.871 Mean :2.419 Mean :2.613
3rd Qu.: 27.750 3rd Qu.:207.50 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000
Max. :100.000 Max. :645.00 Max. :5.000 Max. :5.000 Max. :5.000
NA's :4 NA's :4
调用md.pattern()函数,具体查看缺失值分布
> md.pattern(sleep)
BodyWgt BrainWgt Pred Exp Danger Sleep Span Gest Dream NonD
42 1 1 1 1 1 1 1 1 1 1 0
2 1 1 1 1 1 1 0 1 1 1 1
3 1 1 1 1 1 1 1 0 1 1 1
9 1 1 1 1 1 1 1 1 0 0 2
2 1 1 1 1 1 0 1 1 1 0 2
1 1 1 1 1 1 1 0 0 1 1 2
2 1 1 1 1 1 0 1 1 0 0 3
1 1 1 1 1 1 1 0 1 0 0 3
0 0 0 0 0 4 4 4 12 14 38
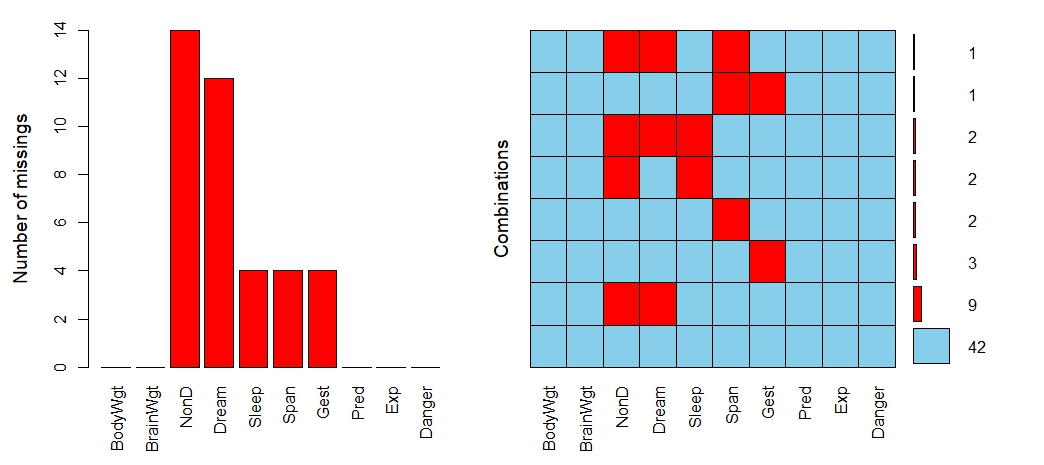
还可以用可视化的方法查看缺失值的分布情况,下面的代码可以输出缺失值的分布情况图
> aggr(sleep,prop=FALSE,numbers=TRUE)
R语言中还有许多函数可以识别缺失值,在R语言中,NA代表缺失值,NaN代表不可能的值,Inf代表正无穷,-Inf代表负无穷,is.na()识别缺失值,is.nan()识别不可能值,is.infinite()识别无穷值,complete.cases()可以识别矩阵或者数据框中没有缺失值的行:
> sum(is.na(sleep))
[1] 38
> sum(complete.cases(sleep))
[1] 42
2、异常值分析
通过对数据进行统计和可视化可以发现数据集中的异常数据,例如下面对银行用户的年龄建立频数直方图:
> hist(age, breaks=100, main="银行账户持有人的年龄分布", xlab="年龄", ylab="频数", col="gray")

从上图可以看出大部分的客户年龄在40岁到60岁之间, 10岁以下的用户也有一些,虽然不太常见但还说得通,可能是父母为孩子设的教育基金。但是左边0岁的或者年龄是负的用户就很不合理了。这就有可能是数据缺失造成的,可能有些用户缺失的年龄值在输入数据时被0替代了。这可能是由于这列数据不接受缺失值。另外,也有可能是因为数据在不同的系统中转移过,而这些系统对缺失的定义各不相同(比如NULL, NA, 0, –1, or –2)。因此,需要对这些年龄异常的帐户进行数据清洗,分析者需要仔细观察这些数据,然后决定是删除这些错误的数据还是看看能不能通过别的信息判断出用户的年龄。
此外,图中还有一些超过一百岁的用户,这可能是打字错误导致的,也有可能是这些帐户已经留给继承人却没有更新。这种情况,就需要进一步检查数据然后再决定应不应该清洗数据。异常的数据可以直接被删除或者用一个年龄阈值进行过滤,超过的数据可以用作未来分析。如果直接删除不可行,则应该寻找数据的规律,然后尝试替代方法。比如,错误的年龄可以用最相近值(分析除了年龄外的数据的差异,然后得到相似的记录)的近似值来代替。
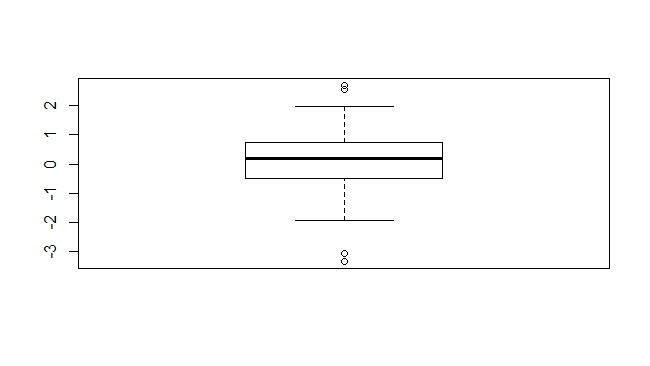
对单变量中异常值的检测还可以使用箱线图,比方下面的例子,首先生成了100个服从标准正太分布的随机数,使用summary()函数查看基本统计量,利用boxplot.stats()函数查看异常值并绘制箱线图,其中在箱线图线外的点基本可以认为是异常点了:
> set.seed(3147)
> x <- rnorm(100)
> summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-3.3154 -0.4837 0.1867 0.1098 0.7120 2.6859
> boxplot.stats(x)$out
[1] -3.315391 2.685922 -3.055717 2.571203
> boxplot(x)