实验目的
了解决策树分类算法的基本原理,并掌握Python语言中实现决策树算法的函数方法
实验原理
决策树(Decision Tree)是一种十分常用的分类算法,是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
实验步骤
本文结构:
- 是什么?
- 有什么算法?
- 数学原理?
- 编码实现算法?
1. 是什么?
简单地理解,就是根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为几类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
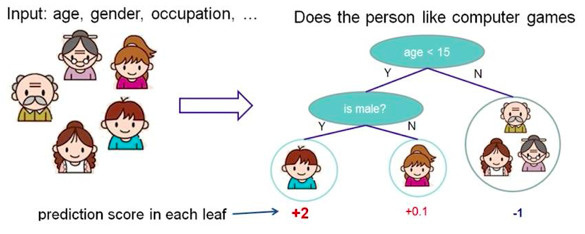
2. 有什么算法?
常用的几种决策树算法有ID3、C4.5、CART:
- ID3:选择信息熵增益最大的feature作为node,实现对数据的归纳分类。
- C4.5:是ID3的一个改进,比ID3准确率高且快,可以处理连续值和有缺失值的feature。
- CART:使用基尼指数的划分准则,通过在每个步骤最大限度降低不纯洁度,CART能够处理孤立点以及能够对空缺值进行处理。
3. 数学原理?
ID3: Iterative Dichotomiser 3
参考
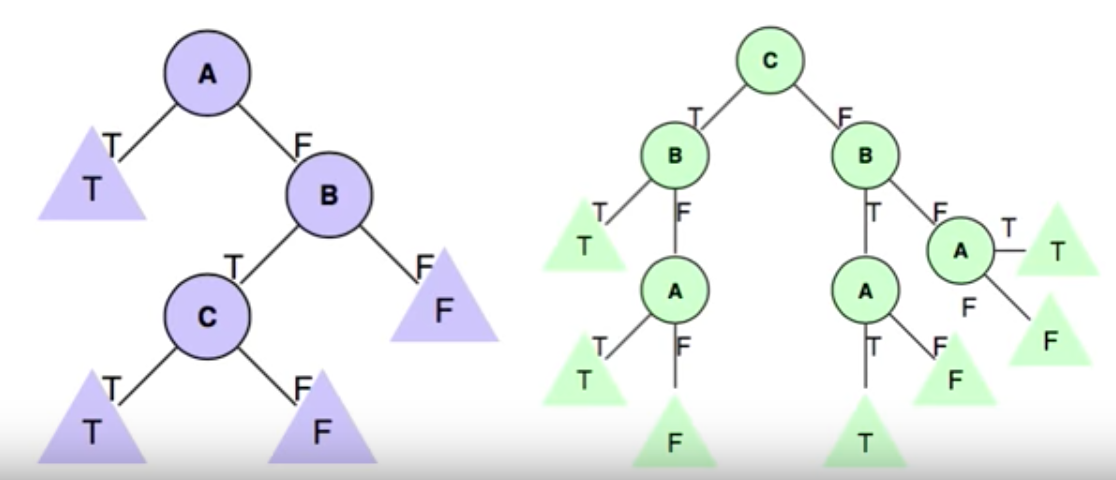
下面这个数据集,可以同时被上面两颗树表示,结果是一样的,而我们更倾向于选择简单的树。
那么怎样做才能使得学习到的树是最简单的呢?

下面是 ID3( Iterative Dichotomiser 3 )的算法:
 例如下面数据集,哪个是最好的 Attribute?
例如下面数据集,哪个是最好的 Attribute?
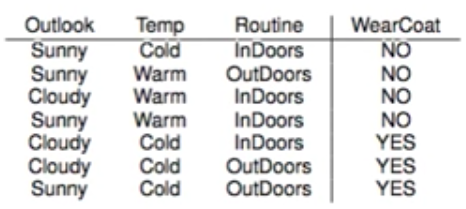
用熵Entropy来衡量:
E(S) 是数据集S的熵
i 指每个结果,即 No,Yes的概率

E越大意味着信息越混乱,我们的目标是要让E最小。
E在0-1之间,如果P+的概率在0.5, 此时E最大,这时候说明信息对我们没有明确的意义,对分类没有帮助。
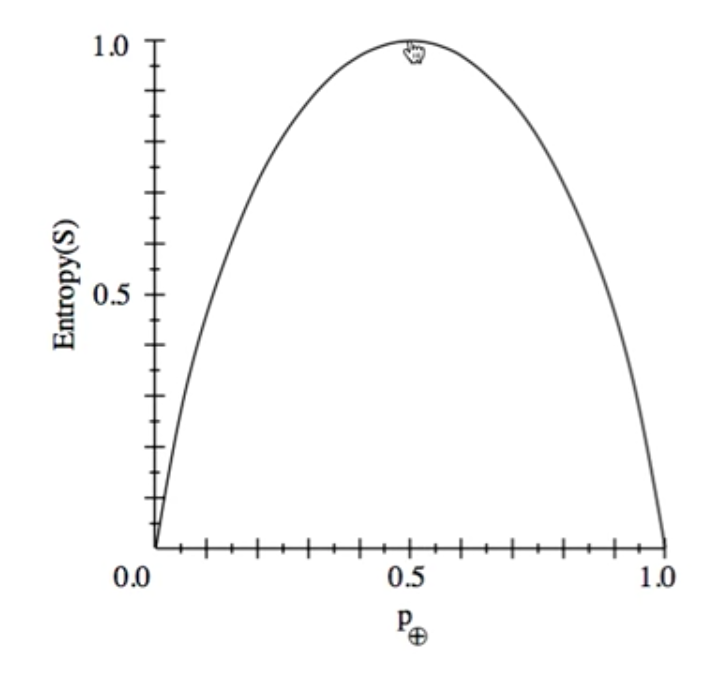
但是我们不仅仅想要变量的E最小,还想要这棵树是 well organized。
所以用到 Gain:信息增益
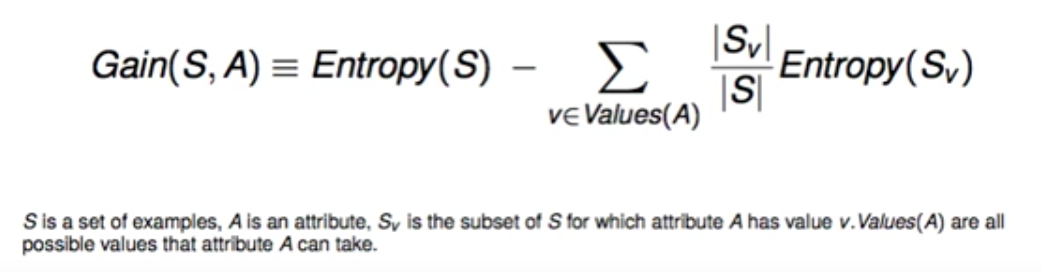
意思是如果我后面要用这个变量的话,它的E会减少多少。
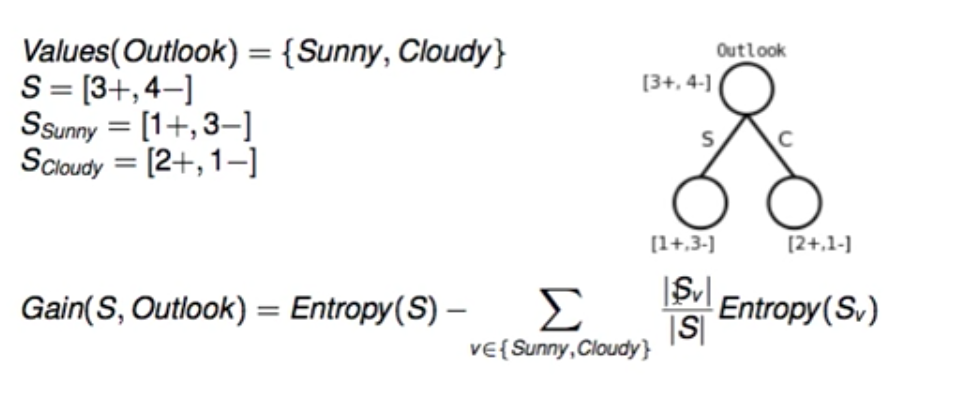
例如下面的数据集:
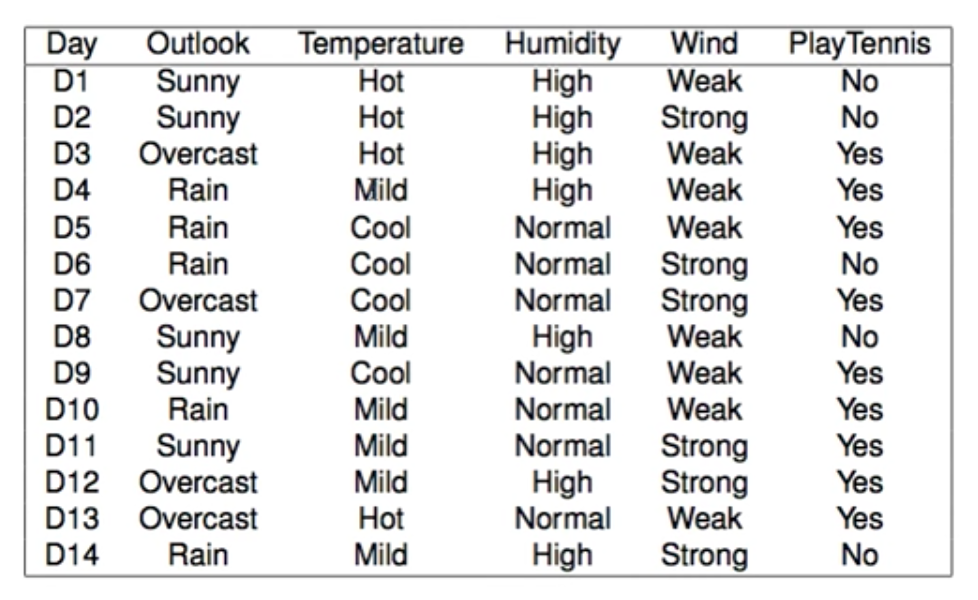
- 先计算四个feature的熵E,及其分支的熵,然后用Gain的公式计算信息增益。
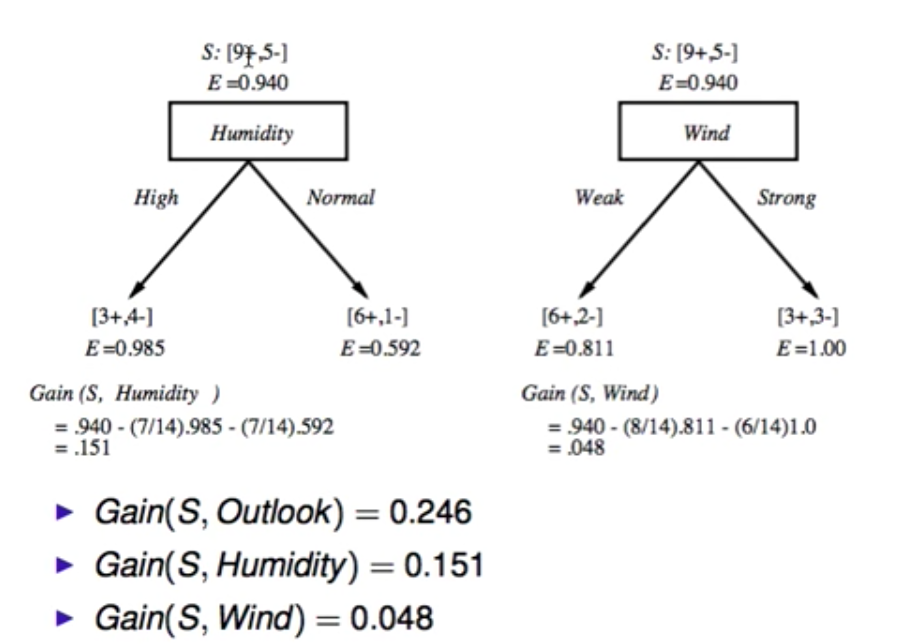
2.再选择Gain最大的特征是 outlook。
3.第一层选择出来后,各个分支再继续选择下一层,计算Gain最大的,例如分支 sunny 的下一层节点是 humidity。
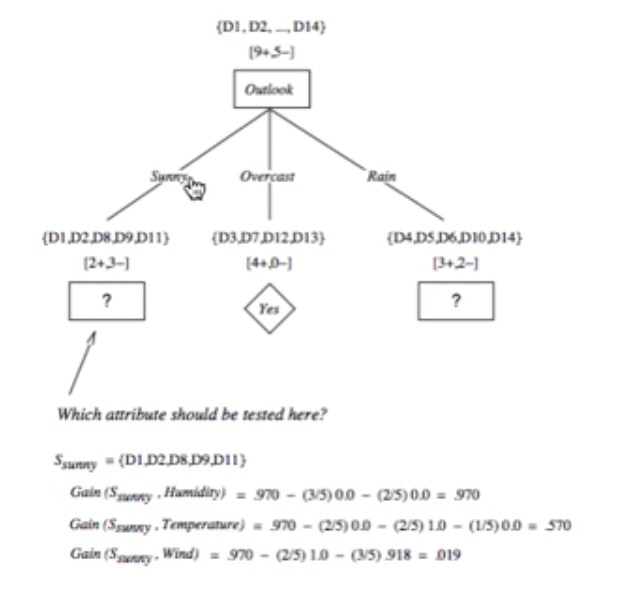
接下来我们应用sklearn的数据集来具体实现一个决策树算法。
首先导入数据集:
- from itertools import product
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn import datasets
- from sklearn.tree import DecisionTreeClassifier
- # 仍然使用自带的iris数据
- iris = datasets.load_iris()
- X = iris.data[:, [0, 2]]
- y = iris.target
训练模型,限制树的最大深度为4:
- # 训练模型,限制树的最大深度4
- clf = DecisionTreeClassifier(max_depth=4)
- #拟合模型
- clf.fit(X, y)
画图:
# 画图
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
- np.arange(y_min, y_max, 0.1))
- Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
- Z = Z.reshape(xx.shape)
- plt.contourf(xx, yy, Z, alpha=0.4)
- plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
- plt.show()
- from IPython.display import Image
- from sklearn import tree
- import pydotplus
- dot_data = tree.export_graphviz(clf, out_file=None,
- feature_names=iris.feature_names,
- class_names=iris.target_names,
- filled=True, rounded=True,
- special_characters=True)
- graph = pydotplus.graph_from_dot_data(dot_data)
- Image(graph.create_png())

 结果为:
结果为:
