实验目的
掌握Python进行数据描述的方法。
实验原理
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
实验步骤
一、创建DataFrme
首先引入Pandas及Numpy:
import pandas as pd
import numpy as np
官方推荐的缩写形式为pd,你可以选择其他任意的名称。 DataFrame是二维的数据结构,其本质是Series的容器,因此,DataFrame可以包含一个索引以及与这些索引联合在一起的Series,由于一个Series中的数据类型是相同的,而不同Series的数据结构可以不同。因此对于DataFrame来说,每一列的数据结构都是相同的,而不同的列之间则可以是不同的数据结构。或者以数据库进行类比,DataFrame中的每一行是一个记录,名称为Index的一个元素,而每一列则为一个字段,是这个记录的一个属性。 创建DataFrame有多种方式:
以字典的字典或Series的字典的结构构建DataFrame,这时候的最外面字典对应的是DataFrame的列,内嵌的字典及Series则是其中每个值。
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
可以看到d是一个字典,其中one的值为Series有3个值,而two为Series有4个值。由d构建的为一个4行2列的DataFrame。其中one只有3个值,因此d行one列为NaN(Not a Number)--Pandas默认的缺失值标记。
从列表的字典构建DataFrame,其中嵌套的每个列表(List)代表的是一个列,字典的名字则是列标签。这里要注意的是每个列表中的元素数量应该相同。否则会报错:
ValueError: arrays must all be same length
从字典的列表构建DataFrame,其中每个字典代表的是每条记录(DataFrame中的一行),字典中每个值对应的是这条记录的相关属性。
d = [{'one' : 1,'two':1},{'one' : 2,'two' : 2},{'one' : 3,'two' : 3},{'two' : 4}]
df = pd.DataFrame(d,index=['a','b','c','d'],columns=['one','two'])
df.index.name='index'
以上的语句与以Series的字典形式创建的DataFrame相同,只是思路略有不同,一个是以列为单位构建,将所有记录的不同属性转化为多个Series,行标签冗余,另一个是以行为单位构建,将每条记录转化为一个字典,列标签冗余。使用这种方式,如果不通过columns指定列的顺序,那么列的顺序会是随机的。
对于从一些已经结构化的数据转化为DataFrame似乎前者更方便,而对于一些需要自己结构化的数据(比如解析Log文件,特别是针对较大数据量时),似乎后者更方便。创建了DataFrame后可以通过index.name属性为DataFrame的索引指定名称。
二、DataFrame转换为其他类型
df.to_dict(outtype='dict')
outtype的参数为‘dict’、‘list’、‘series’和‘records’。 dict返回的是dict of dict;list返回的是列表的字典;series返回的是序列的字典;records返回的是字典的列表
查看数据
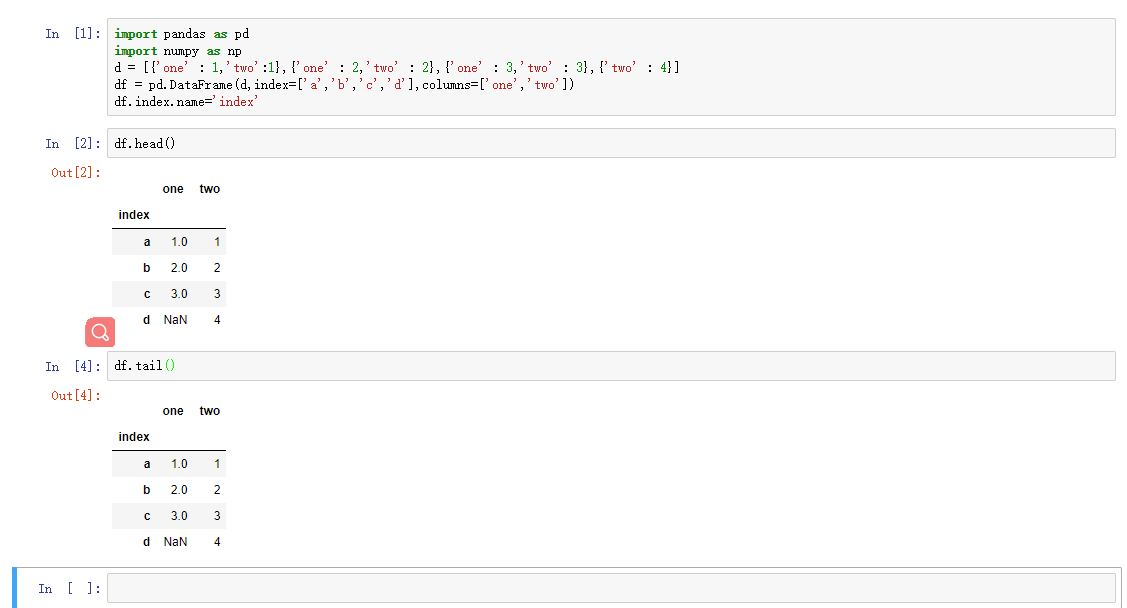
head和tail方法可以显示DataFrame前N条和后N条记录,N为对应的参数,默认值为5。这通常是拿到DataFrame后的第一个命令,可以方便的了解数据内容和含义。
df.head()
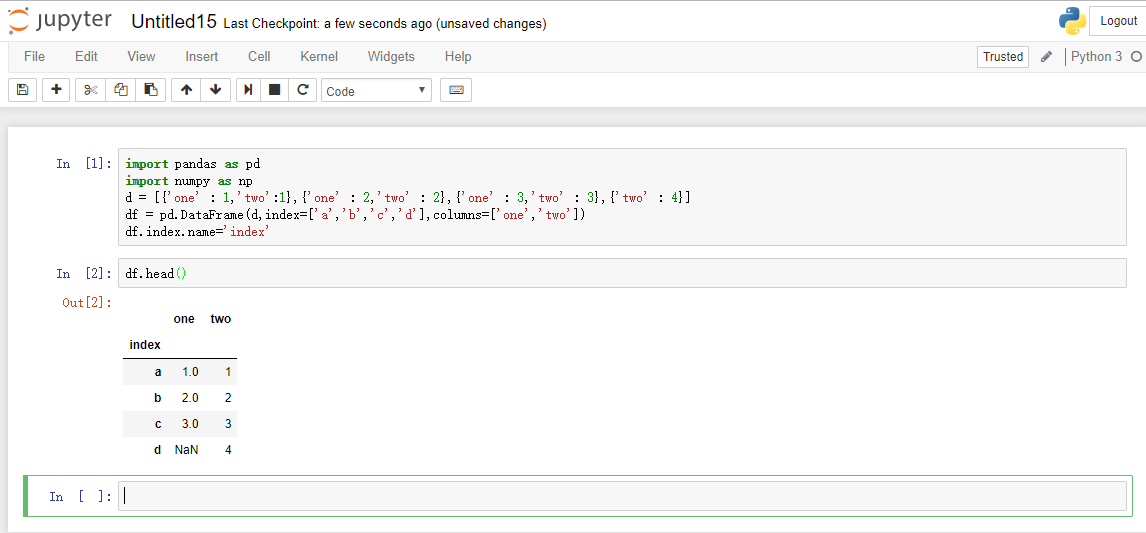
df.tail()
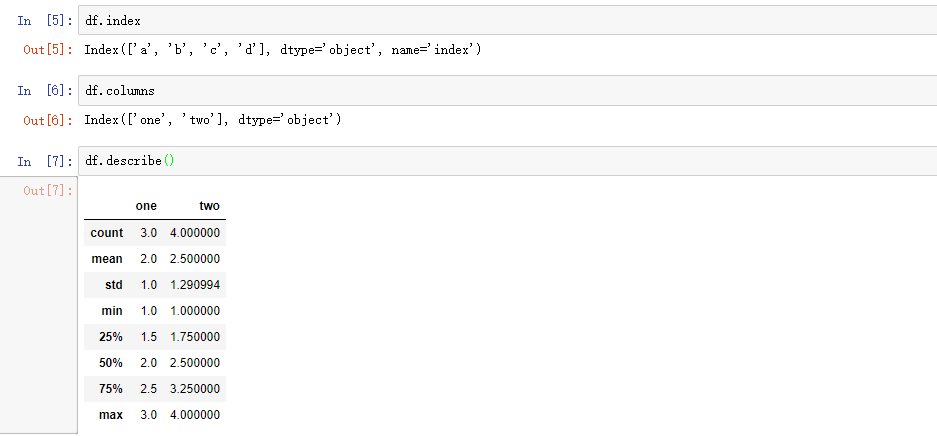 排序
排序
DataFrame提供了多种排序方式。
df.sort_index(axis=1, ascending=False)
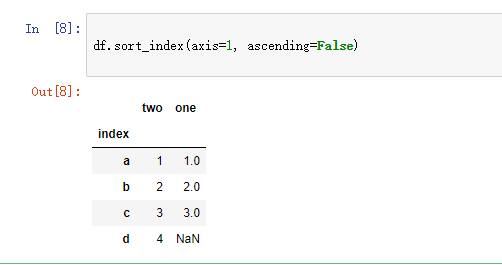
sort_index可以以轴的标签进行排序。axis是指用于排序的轴,可选的值有0和1,默认为0即行标签(Y轴),1为按照列标签排序。 ascending是排序方式,默认为True即降序排列。
df.sort(columns='two')
df.sort(columns=['one','two'],ascending=[0,1])
DataFrame也提供按照指定列进行排序,可以仅指定一个列作为排序标准(以单独列名作为columns的参数),也可以进行多重排序(columns的参数为一个列名的List,列名的出现顺序决定排序中的优先级),在多重排序中ascending参数也为一个List,分别与columns中的List元素对应。
注意:python2中print语句不加括号,python3中print语句打印内容要加括号!