不同算法的比较
实验目的
- 复习多种分类算法
- 比较多种分类算法,了解各个的优缺点
- 学会灵活使用各种分类算法
KNN算法
一、KNN算法的优点
1、KNN是一种在线技术,新数据可以直接加入数据集而不必进行重新训练
2、KNN理论简单,容易实现
二、KNN算法的缺点
1、对于样本容量大的数据集计算量比较大。
2、样本不平衡时,预测偏差比较大。如:某一类的样本比较少,而其它类样本比较多。
3、KNN每一次分类都会重新进行一次全局运算。
4、k值大小的选择。
支持向量机(SVM)
一、 SVM优点
1、解决小样本下机器学习问题。
2、解决非线性问题。
3、无局部极小值问题。(相对于神经网络等算法)
4、可以很好的处理高维数据集。
5、泛化能力比较强。
二、SVM缺点
1、对于核函数的高维映射解释力不强,尤其是径向基函数。
2、对缺失数据敏感。
决策树
一、 决策树优点
1、决策树易于理解和解释,可以可视化分析,容易提取出规则。
2、可以同时处理标称型和数值型数据。
3、测试数据集时,运行速度比较快。
4、决策树可以很好的扩展到大型数据库中,同时它的大小独立于数据库大小。
二、决策树缺点
1、对缺失数据处理比较困难。
2、容易出现过拟合问题。
3、忽略数据集中属性的相互关联。
4、ID3算法计算信息增益时结果偏向数值比较多的特征。
三、改进措施
1、对决策树进行剪枝。可以采用交叉验证法和加入正则化的方法。
2、使用基于决策树的combination算法,如bagging算法,randomforest算法,可以解决过拟合的问题
四、应用领域
企业管理实践,企业投资决策,由于决策树很好的分析能力,在决策过程应用较多。
人工神经网络
一、 神经网络优点
1、分类准确度高,学习能力极强。
2、对噪声数据鲁棒性和容错性较强。
3、有联想能力,能逼近任意非线性关系。
二、神经网络缺点
1、神经网络参数较多,权值和阈值。
2、黑盒过程,不能观察中间结果。
3、学习过程比较长,有可能陷入局部极小值。
三、人工神经网络应用领域
目前深度神经网络已经应用与计算机视觉,自然语言处理,语音识别等领域并取得很好的效果。
实验步骤
本实例测试多种分类算法,如下:
classifiers = {'NB':naive_bayes_classifier,
'KNN':knn_classifier,
'LR':logistic_regression_classifier,
'RF':random_forest_classifier,
'DT':decision_tree_classifier,
'SVM':svm_classifier,
'SVMCV':svm_cross_validation,
'GBDT':gradient_boosting_classifier
}
代码如下
#载入需要的库
import sys
import os
import ime
from slearn import metrics
import numpy as np
import pickle
#定义朴素贝叶斯分类器
def naive_bayes_classifier(train_x, train_y):
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB(alpha=0.01)
model.fit(train_x, train_y)
return model
#定义KNN分类器
def knn_classifier(train_x, train_y):
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(train_x, train_y)
return model
# 随机森林分类器
def random_forest_classifier(train_x, train_y):
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=8)
model.fit(train_x, train_y)
return model
#定义逻辑回归分类器
def logistic_regression_classifier(train_x, train_y):
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2')
model.fit(train_x, train_y)
return model
#定义决策树分类器
def decision_tree_classifier(train_x, train_y):
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(train_x, train_y)
return model
# GBDT(Gradient Boosting Decision Tree)分类器
def gradient_boosting_classifier(train_x, train_y):
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=200)
model.fit(train_x, train_y)
return model
# SVM分类器
def svm_classifier(train_x, train_y):
from sklearn.svm import SVC
model = SVC(kernel='rbf', probability=True)
model.fit(train_x, train_y)
return model
# SVM Classifier using cross validation
def svm_cross_validation(train_x, train_y):
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
model = SVC(kernel='rbf', probability=True)
param_grid = {'C': [1e-3, 1e-2, 1e-1, 1, 10, 100, 1000], 'gamma': [0.001, 0.0001]}
grid_search = GridSearchCV(model, param_grid, n_jobs = 1, verbose=1)
grid_search.fit(train_x, train_y)
best_parameters = grid_search.best_estimator_.get_params()
for para, val in best_parameters.items():
print(para, val)
model = SVC(kernel='rbf', C=best_parameters['C'], gamma=best_parameters['gamma'], probability=True)
model.fit(train_x, train_y)
return model
#读取数据
def read_data(data_file):
import gzip
f = gzip.open(data_file, "rb")
train, val, test = pickle.load(f,encoding='iso-8859-1')
f.close()
train_x = train[0]
train_y = train[1]
test_x = test[0]
test_y = test[1]
return train_x, train_y, test_x, test_y
#分析过程代码如下
data_file = "mnist.pkl.gz"
thresh = 0.5
model_save_file = None
model_save = {}
#test_classifiers = ['GBDT','NB', 'LR', 'RF', 'DT','KNN','SVM']
test_classifiers=['NB','LR','RF','DT']
classifiers = {'NB':naive_bayes_classifier,
'KNN':knn_classifier,
'LR':logistic_regression_classifier,
'RF':random_forest_classifier,
'DT':decision_tree_classifier,
'SVM':svm_classifier,
'SVMCV':svm_cross_validation,
'GBDT':gradient_boosting_classifier
}
print('reading training and testing data...')
train_x, train_y, test_x, test_y = read_data(data_file)
num_train, num_feat = train_x.shape
num_test, num_feat = test_x.shape
is_binary_class = (len(np.unique(train_y)) == 2)
print(is_binary_class)
print('******************** Data Info *********************')
print('#training data: %d, #testing_data: %d, dimension: %d' % (num_train, num_test, num_feat))
train_times=[]
accuracys=[]
for classifier in test_classifiers:
print('******************* %s ********************' % classifier)
start_time = time.time()
model = classifiers[classifier](train_x, train_y)
print('training took %fs!' % (time.time() - start_time))
train_times.append(time.time() - start_time)
start_time = time.time()
predict = model.predict(test_x)
print("predict took %fs" % (time.time() - start_time))
if model_save_file != None:
model_save[classifier] = model
if is_binary_class:
precision = metrics.precision_score(test_y, predict)
recall = metrics.recall_score(test_y, predict)
print('precision: %.2f%%, recall: %.2f%%' % (100 * precision, 100 * recall))
accuracy = metrics.accuracy_score(test_y, predict)
accuracys.append(accuracy)
print('accuracy: %.2f%%' % (100 * accuracy))
可视化结果
#结果整理
import pandas as pd
visualization=pd.DataFrame([test_classifiers,train_times,accuracys])
visualization=visualization.T
visualization.columns=["names","times","accuracy"]
visualization
#简单可视化
import matplotlib.pyplot as plt
#获得模型训练时间可视化对比
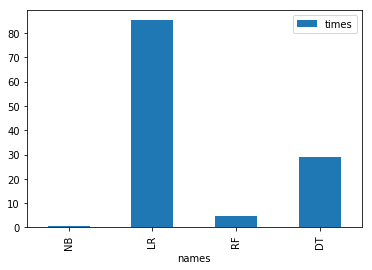
visualization.plot(x="names",y="times", kind='bar')
plt.show()
#获得模型准确率可视化对比
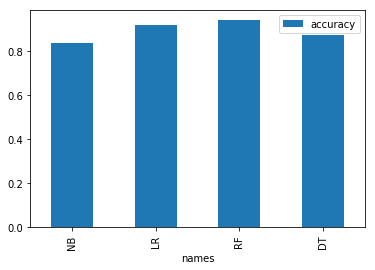
visualization.plot(x="names",y="accuracy", kind='bar')
plt.show()
本次使用mnist手写体库进行实验:http://deeplearning.net/data/mnist/mnist.pkl.gz。共5万训练样本和1万测试样本。
代码运行结果如下:
reading training and testing data...
******************** Data Info *********************
#training data: 50000, #testing_data: 10000, dimension: 784
******************* NB ********************
training took 0.287000s!
accuracy: 83.69%
******************* KNN ********************
training took 31.991000s!
accuracy: 96.64%
******************* LR ********************
training took 101.282000s!
accuracy: 91.99%
******************* RF ********************
training took 5.442000s!
accuracy: 93.78%
******************* DT ********************
training took 28.326000s!
accuracy: 87.23%
******************* SVM ********************
training took 3152.369000s!
accuracy: 94.35%
******************* GBDT ********************
training took 7623.761000s!
accuracy: 96.18%