实验目的
掌握Python语言对数据集数据质量的分析方法
实验原理
在对数据进行分析和挖掘之前,首先要对数据进行预处理,将数据集中含有的脏数据处理掉,因此,数据质量分析是数据分析和数据挖掘的基础,只有有效的数据才能挖掘出真正的信息。
数据质量分析主要是以数据提供信息的正确性和有效性为目标,本节教程主要介绍缺失值分析和异常值分析。
实验步骤
处理缺失值
注意:python2中print语句不加括号,python3中print语句打印内容要加括号!
现实中的数据总是存在或多或少的缺失值现象。原因多种多样,可能是数据收集阶段发生错误,也可能数据调研阶段某些选项没有被填写。不论是什么原因造成的缺失值,我们都统一将其看做空格或者用NaN(Not a Number)表示的占位符。
不幸地是,大多数计算工具不能处理缺失值,即使我们忽略缺失值也不能产生预测结果。因此,我们必须认真对待缺失值问题。在讨论处理缺失值的方法之前,我们先创建一个例子,以便更好地理解缺失值问题:
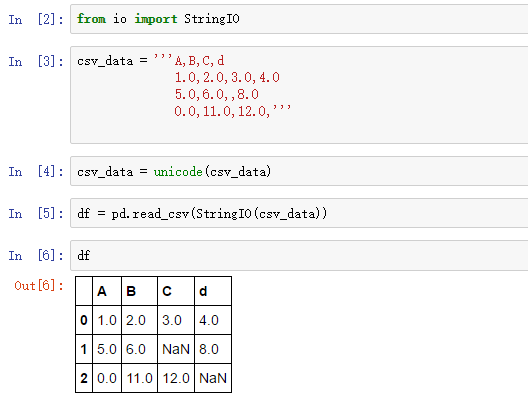
上面的代码,我们创建了一个csv格式的变量csv_data, 然后读入DataFrame对象,注意其中两个缺失值被NaN替代了。
如果DataFrame对象包含的数据很多,人工来查找NaN就不现实了。我们可以使用isnull方法来返回一个值为布尔类型的DataFrame,判断每个元素是否缺失,如果元素缺失,值为True。然后使用sum方法,我们就能得到DataFrame中每一列的缺失值个数,还是看代码理解吧:
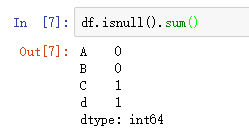
现在我们知道如果统计DataFrame每一列中的缺失值个数。下一节我们学习几种处理缺失值的策略。
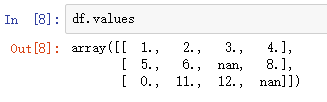
Note虽然scikit-learn和NumPy数组结合的很方便,但是预处理时还是推荐使用pandas的DataFrame格式而非NumPy数组。由DataFrame对象得到NumPy数组很方便,直接通过values属性即可,然后就可以用sklearn中的算法了:
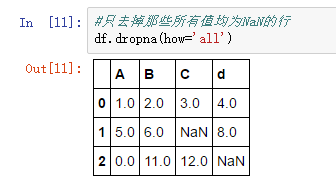
消除带有缺失值的特征或样本
处理缺失值最简单的手段无疑是直接将带有缺失值的特征(列)或样本(行)从数据集中去掉。去掉行可以通过dropna方法:

去掉列同样用dropna方法,只不过将参数axis设置为1:

dropna方法包含多个参数:

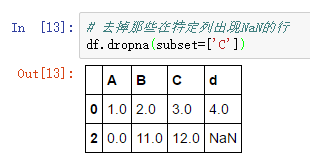
虽然移除缺失值的操作很简单,但是这样做的缺点也很明显,比如,如果每一行都有一个缺失值,那整个数据集都被移除了。或者移除了过多的特征。
改写缺失值
用移除法处理缺失值的缺点很明显,过于暴力,会丢掉很多数据信息。怎样保留那些非缺失值数据的同时处理缺失值呢?这就是插入法,用一个估计值来替代缺失值。最常用的是平均估计法,即用整个特征列的平均值代替这一列的缺失值。
使用sklearn中的Imputer类能很容易实现此方法:
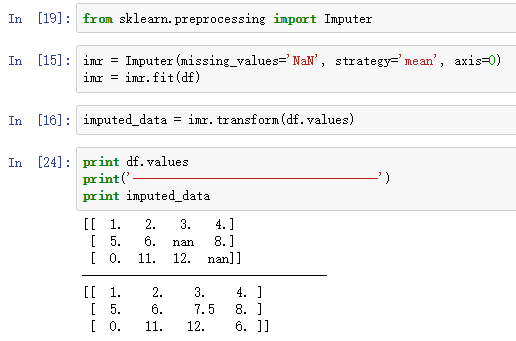
先计算每一列的平均值,然后用相应列的平均值来替换NaN。如果将参数axis=0改为axis=1,则会计算每个样本的所有特种的平均值。参数strategy的其他取值包括median和most_frequent。most_frequent对于处理分类数据类型的缺失值很有用。