实验目的
了解支持向量机(svm)分类算法的基本原理,并掌握R语言中实现svm算法的函数方法
实验原理
支持向量机首先是一种二分类模型,它的基本思想是找到线性空间中的一个超平面,可以将两类别正确分离并使几何间隔最大。当然能线性正确分隔的数据集毕竟很少,如果数据集线性不可分,即存在特异点,除去这些特异点后,数据集是线性可分的,则可以引入松弛变量和惩罚因子,使得分离间隔尽量大的同时误分类的点数目尽量少。对于非线性的分类问题,可以利用核技巧的方法,将数据集映射到高维空间中,在高维空间中训练数据集,找到能使分离间隔较大并且误分类点较少的超平面,这种方法叫做非线性支持向量机。支持向量机中对分离超平面的求解可以形式化为凸优化问题的求解,下面通过调用R语言中e1071包中的函数svm()展示支持向量机。
实验步骤
首先安装e1071包并加载
> install.packages("e1071")
> library(e1071)
导入iris数据集
> data(iris)
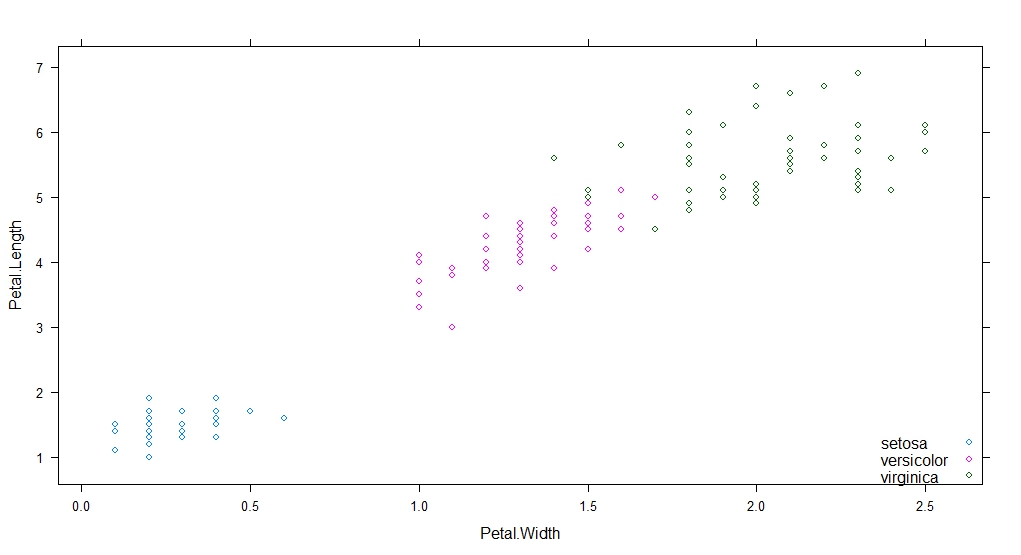
首先通过散点图观察数据集的大致分布情况,此步需要加载lattice包,因此先安装
> install.packages("lattice")
> library(lattice)
> xyplot(Petal.Length ~ Petal.Width, data = iris, groups = Species, auto.key=list(corner=c(1,0)))
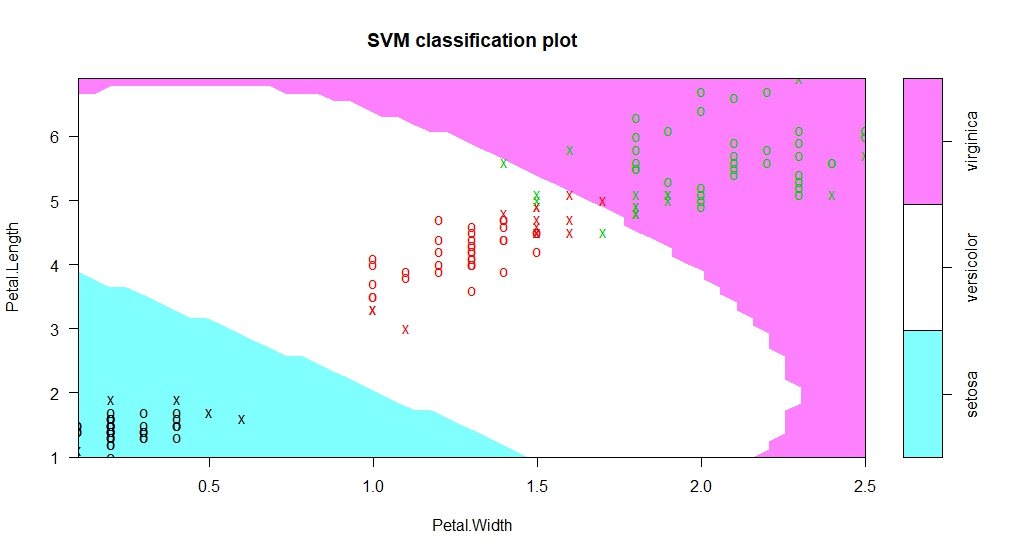
调用svm函数并观察分类后的超平面
> svm_model <- svm(Species~Petal.Length+Petal.Width,data=iris)
> plot(svm_model,iris,Petal.Length~Petal.Width)