实验二:支持向量机分类实验
一 实验目的
- 了解支持向量机的基本原理,几何间隔函数间隔等基础概念
- 了解支持向量机的优缺点和适用场景
- 学会使用Python语言建立SVM分类模型
二 实验原理
支持向量机(support vector machines,SVM)是一种二类分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;支持向量机还包括核技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划(convex quadratic programming,不怕,附录有解释)的问题,也等价于正则化的合页损失函数(后面也有解释)的最小化问题。支持向量机的学习算法是求解凸二次规划的最优化算法。
下文将带您学习到支持向量机如何工作,以及如何利用R语言实现支持向量机分类算法。
线性分类
下面举个简单的例子,如下图所示,现在有一个二维平面,平面上有两种不同的数据,分别用圈和叉表示。由于这些数据是线性可分的,所以可以用一条直线将这两类数据分开,这条直线就相当于一个超平面,超平面一边的数据点所对应的y全是 -1 ,另一边所对应的y全是1。
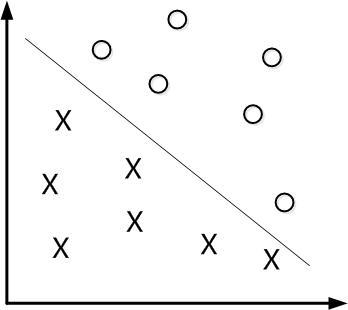
这个超平面可以用分类函数
函数间隔与几何间隔
在超平面w*x+b=0确定的情况下,|w*x+b|能够表示点x到距离超平面的远近,而通过观察w*x+b的符号与类标记y的符号是否一致可判断分类是否正确,所以,可以用(y*(w*x+b))的正负性来判定或表示分类的正确性。于此,我们便引出了函数间隔(functional margin)的概念。
定义函数间隔(用

而超平面(w,b)关于T中所有样本点(xi,yi)的函数间隔最小值(其中,x是特征,y是结果标签,i表示第i个样本),便为超平面(w, b)关于训练数据集T的函数间隔:
但这样定义的函数间隔有问题,即如果成比例的改变w和b(如将它们改成2w和2b),则函数间隔的值f(x)却变成了原来的2倍(虽然此时超平面没有改变),所以只有函数间隔还远远不够。事实上,我们可以对法向量w加些约束条件,从而引出真正定义点到超平面的距离--几何间隔(geometrical margin)的概念。假定对于一个点 x ,令其垂直投影到超平面上的对应点为 x0 ,w 是垂直于超平面的一个向量,

有
又由于 x0 是超平面上的点,满足 f(x0)=0 ,代入超平面的方程



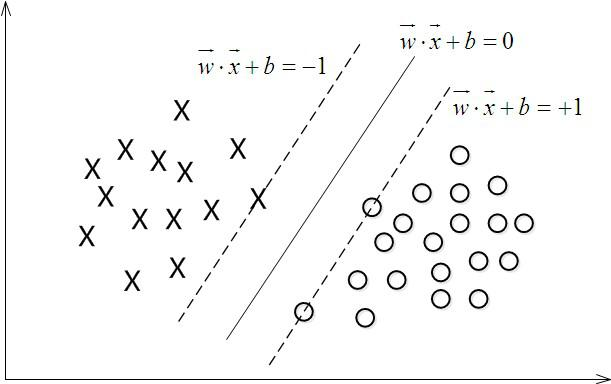
最大间隔分类器
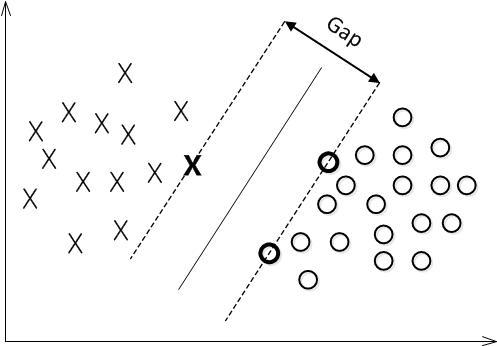
对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔如下图中的gap / 2所示。
通过由前面的分析可知:函数间隔不适合用来最大化间隔值,因为在超平面固定以后,可以等比例地缩放w的长度和b的值,这样可以使得

,使得在缩放w和b的时候几何间隔
于是最大间隔分类器(maximum margin classifier)的目标函数可以定义为: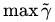 同时需满足一些条件,根据间隔的定义,有
同时需满足一些条件,根据间隔的定义,有

其中,s.t.,即subject to的意思,它导出的是约束条件。回顾下几何间隔的定义
 这个目标函数便是在相应的约束条件
这个目标函数便是在相应的约束条件
如下图所示,中间的实线便是寻找到的最优超平面(Optimal Hyper Plane),其到两条虚线的距离相等,这个距离便是几何间隔


Python代码实例
SVC,NuSVC和LinearSVC是能够对数据集执行多分类的类。
SVC和NuSVC是类似的方法,但是接受的参数集有稍微不同并且具有不同的数学公式。 另一方面,LinearSVC是线性内核的支持向量分类的另一个实现。 请注意,LinearSVC不接受关键字内核,因为这被假定为线性的。 它还缺少SVC和NuSVC的一些成员,像support_。
和其他分类器一样,SVC,NuSVC和LinearSVC作为输入两个数组:保存训练样本的大小为[n_samples,n_features]的数组X和类标签(字符串或整数)的大小为[n_samples]数组y:
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
得到训练好的模型之后,我们可以用模型来预测新样本的类别:
>>> clf.predict([[2., 2.]])
array([1])
支持向量机的决策功能取决于训练数据的一些子集,称为支持向量。 这些支持向量的一些属性可以在成员support_vectors_,support_和n_support中找到:
>>> # get support vectors
>>> clf.support_vectors_
array([[ 0., 0.],
[ 1., 1.]])
>>> # get indices of support vectors
>>> clf.support_
array([0, 1]...)
>>> # get number of support vectors for each class
>>> clf.n_support_
array([1, 1]...)
SVC和NuSVC实施了“一对一”方法,用于多类分类。 如果n_class是类的数目,那么构造n_class *(n_class - 1)/ 2分类,并且每个类都从两个类中训练数据。 为了与其他分类器提供一致的界面,decision_function_shape选项允许将“一对一”分类器的结果聚合到shape(n_samples,n_classes)的决策函数中:
>>> X = [[0], [1], [2], [3]]
>>> Y = [0, 1, 2, 3]
>>> clf = svm.SVC(decision_function_shape='ovo')
>>> clf.fit(X, Y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovo', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes: 4*3/2 = 6
6
>>> clf.decision_function_shape = "ovr"
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes
4
另一方面,LinearSVC实现了“one-vs-the-rest”多类策略,从而训练n_class模型。 如果只有两个类别,只有一个模型被训练:
>>> lin_clf = svm.LinearSVC()
>>> lin_clf.fit(X, Y)
LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=1000,
multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,
verbose=0)
>>> dec = lin_clf.decision_function([[1]])
>>> dec.shape[1]
4
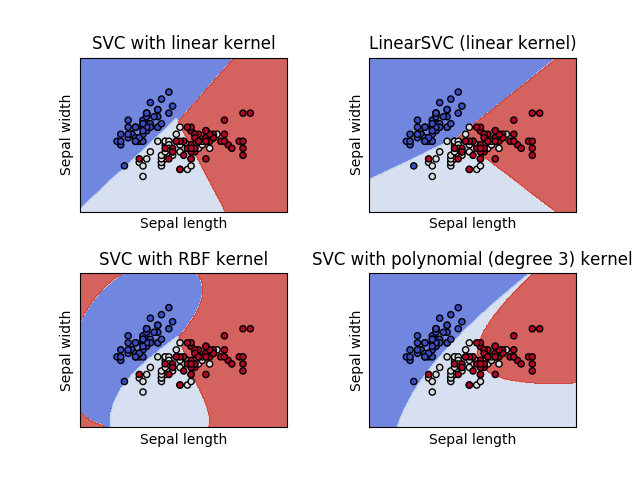
以下是一个完整的实例用于显示多种svm分类器在IRIS数据集上的支持向量
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
def make_meshgrid(x, y, h=.02):
"""Create a mesh of points to plot in
Parameters
----------
x: data to base x-axis meshgrid on
y: data to base y-axis meshgrid on
h: stepsize for meshgrid, optional
Returns
-------
xx, yy : ndarray
"""
x_min, x_max = x.min() - 1, x.max() + 1
y_min, y_max = y.min() - 1, y.max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contours(ax, clf, xx, yy, **params):
"""Plot the decision boundaries for a classifier.
Parameters
----------
ax: matplotlib axes object
clf: a classifier
xx: meshgrid ndarray
yy: meshgrid ndarray
params: dictionary of params to pass to contourf, optional
"""
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = ax.contourf(xx, yy, Z, **params)
return out
# import some data to play with
iris = datasets.load_iris()
# Take the first two features. We could avoid this by using a two-dim dataset
X = iris.data[:, :2]
y = iris.target
# we create an instance of SVM and fit out data. We do not scale our
# data since we want to plot the support vectors
C = 1.0 # SVM regularization parameter
models = (svm.SVC(kernel='linear', C=C),
svm.LinearSVC(C=C),
svm.SVC(kernel='rbf', gamma=0.7, C=C),
svm.SVC(kernel='poly', degree=3, C=C))
models = (clf.fit(X, y) for clf in models)
# title for the plots
titles = ('SVC with linear kernel',
'LinearSVC (linear kernel)',
'SVC with RBF kernel',
'SVC with polynomial (degree 3) kernel')
# Set-up 2x2 grid for plotting.
fig, sub = plt.subplots(2, 2)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
X0, X1 = X[:, 0], X[:, 1]
xx, yy = make_meshgrid(X0, X1)
for clf, title, ax in zip(models, titles, sub.flatten()):
plot_contours(ax, clf, xx, yy,
cmap=plt.cm.coolwarm, alpha=0.8)
ax.scatter(X0, X1, c=y, cmap=plt.cm.coolwarm, s=20, edgecolors='k')
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xlabel('Sepal length')
ax.set_ylabel('Sepal width')
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(title)
plt.show()
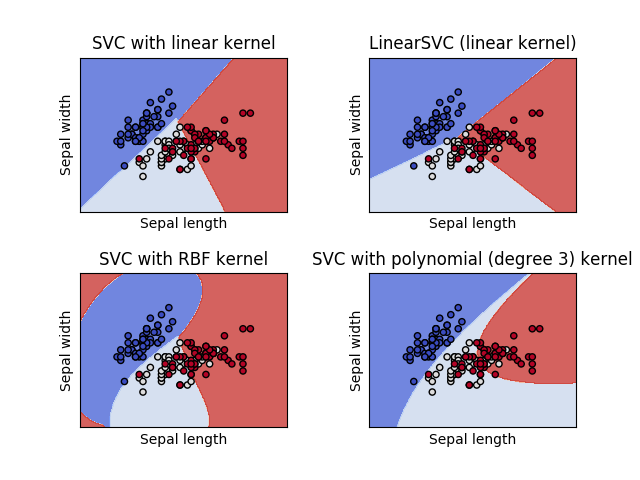
四 常见问题:
支持向量机如何工作?
简单介绍下支持向量机是做什么的:假设你的数据点分为两类,支持向量机试图寻找最优的一条线(超平面),使得离这条线最近的点与其他类中的点的距离最大。有些时候,一个类的边界上的点可能越过超平面落在了错误的一边,或者和超平面重合,这种情况下,需要将这些点的权重降低,以减小它们的重要性。这种情况下,“支持向量”就是那些落在分离超平面边缘的数据点形成的线
无法确定分类线(线性超平面)时该怎么办?
此时可以将数据点投影到一个高维空间,在高维空间中它们可能就变得线性可分了。它会将问题作为一个带约束的最优化问题来定义和解决,其目的是为了最大化两个类的边界之间的距离。我的数据点多于两个类时该怎么办?
此时支持向量机仍将问题看做一个二元分类问题,但这次会有多个支持向量机用来两两区分每一个类,直到所有的类之间都有区别。