实验目的
熟悉迭代式MapReduce的概念,可以写简单的迭代式MapReduce,以PageRank为例子。
实验原理
传统的MapReduce框架把一个作业的执行过程分为两个阶段:map和reduce,在map阶段,每个map task读取一个block,并调用map()函数进行处理,然后将结果写到本地磁盘(注意,不是HDFS)上;在reduce阶段,每个reduce task远程的从map task所在节点上读取数据,调用reduce()函数进行数据处理,并将最终结果写到HDFS。从以上过程可以看出,map阶段和reduce阶段的结果均要写磁盘,这虽然会降低系统性能,但可以提高可靠性。正是由于这个原因,传统的MapReduce不能显式地支持迭代编程,如果用户硬要在传统MapReduce上运行迭代式作业,性能将非常低。为此,不少改进型的MapReduce出现了,它们能很好地支持迭代式开发。
在数据挖掘,信息检索等领域,有很多算法需要多次迭代,其中两个常见的作业,一个是PageRank,另一个是SSSP(Single Source Shortest Path)。PageRank是网页排名算法,介绍见https://baike.baidu.com/item/google%20pagerank/2465380?fr=aladdin&fromid=111004&fromtitle=pagerank。
实验步骤
步骤1.启动Hadoop和Eclipse。
#cd /usr/local/hadoop
#sbin/start-dfs.sh
步骤2.了解PageRank用mapreduce实现的基本思路。
举例:
假设网页 A 的内容中有网页 B,C 和 D 的链接,并且 A 的 PageRank的值为0.25。
那接下里我们就可以计算在网页 A 中的其他网页的PageRank的值了。我们拿网页 B 来进行说明,
在网页 A 中的网页 B 的 PageRank 为 0.25 * (1/n) 其中n为网页 A 中网页链接数,结果则为 0.25*(1/3)。
可以简单理解为A的PageRank被B,C 和 D 平分了,B分到了0.25的三分之一。
然后将所有网页中的关于网页B的pagerank值求出来,就是网页B真实的pagerank了。
但是上面的例子没有考虑到如下的特殊情况:
1 网页A中只有指向自己的网页链接。
2 网页A中没有任何链接。
如果出现以上情况,会导致pagerank结果不准确。
所以出现了下面的公式:
result = sum * n + (1-n)/N
sum 为上面计算出来的,如网页B在所有网页中的pagerank值的总和。
n 可以理解为停留在当前网页继续进行网页跳转浏览的概率
1-n 可以理解为不访问当前网页的任何链接,从浏览器的地址栏输入,转去其他网页的概率。
N 为网页的数量
下面介绍通过MapReduce实现PageRank
简单的流程分析:
Map
取一行数据进行说明
A B C D网页A中有网页B,C,D的链接;
刚开始给网页A一个默认的pagerank值,然后根据这个值计算其他网页链接在网页A中的PageRank。处理后的数据如下:
A 0.25 B C D
B 0.25*(1/3)
C 0.25*(1/3)
D 0.25*(1/3)
Reduce
然后通过 Reduce 计算出各个网页在其他网页中的 PageRank 的总和 sum,然后代入公式计算实际的PageRank,并更新 A 0.25 B C D 中的数据,这里将0.25更新为计算出来真实的 PageRank。
重复计算各个网页的 PageRank 的值,直到 PageRank 的结果收敛,值趋于稳定。
A 0.25 B C D =>A ? B C D
步骤3.在当前目录新建文件pr.txt,输入下面内容,以tap键作为第一列和第二列的分隔符,1个空格作为第二列和第三列的分隔符。
baidu 10.00 google,sina,nefu
google 10.00 baidu
sina 10.00 google
nefu 10.00 sina,google
步骤4.在eclipse中DFS Locations下localhost下新建目录pagerank,在pagerank下新建目录input,将pr.txt用shell代码存入HDFS。
#bin/hdfs -dfs -put pr.txt /pagerank/input
步骤5.打开eclipse,在eclipse中File->New->Other->Map/Reduce->Map/Reduce Project,新建项目PageRank,然后新建包PageRank,并新建文件PageRank.java.编写代码。
package PageRank;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class PageRank {
//枚举计数器
static enum PageCount{
Count,TotalPR
}
//map函数
public static class Map extends Mapper < LongWritable , Text , Text , Text >{
protected void map(LongWritable key, Text value , Context context) throws IOException, InterruptedException{
//任务计数器加1
context.getCounter(PageCount.Count).increment(1);
//每一行分隔开来,返回数组
String[] kv = value.toString().split("\t");
//当前网页为key,pr值和链接网页为value
String _key = kv[0];
String _value = kv[1];
//pr和链接网页以空格分隔,返回数组
String _PRnLink[] = _value.split(" ");
String pr = _PRnLink[0];
String link = _PRnLink[1];
context.write(new Text(_key),new Text(link));
//链接网页以逗号分隔,返回数组
String[] site = link.split(",");
//计算(1-n)/N
float score = Float.valueOf(pr)/(site.length)*1.0f;
for(int i=0;i<site.length;i++){
context.write(new Text(site[i]), new Text(String.valueOf(score)));
}
}
}
//reduce函数
public static class Reduce extends Reducer < Text , Text , Text, Text>{
protected void reduce(Text key , Iterable<Text> values ,Context context) throws IOException, InterruptedException{
StringBuilder sb = new StringBuilder();
float factor = 0.85f; //阻尼因子
float pr = 0f;
//遍历一个网页的链接网页
for(Text val : values){
String value = val.toString();
int s = value.indexOf(".");
if(s != -1){
pr += Float.valueOf(value);
}else{
//链接网页分隔返回数组
String site[] = value.split(",");
int _len = site.length;
//定义输出格式,输出链接网页,以逗号分隔
for(int k=0;k<_len;k++){
sb.append(site[k]);
sb.append(",");
}
}
}
//计算pr值
pr = ((1-factor)+(factor*(pr)));
context.getCounter(PageCount.TotalPR).increment((int)(pr*1000));
String output = pr+" "+sb.toString();
context.write(key, new Text(output));
}
}
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
String input,output;
int threshold = 100;
int iteration = 0;
//定义迭代次数
int iterationLimit = 10;
boolean status = false;
while(iteration < iterationLimit){
//展开反复迭代 注意输入输出的路径
if((iteration % 2) == 0){
input = "hdfs://localhost:9000/output_pr/p*";
output = "hdfs://localhost:9000/output_pr2";
}else{
input = "hdfs://localhost:9000/output_pr2/p*";
output = "hdfs://localhost:9000/output_pr";
}
Configuration conf = new Configuration();
final FileSystem filesystem = FileSystem.get(new URI(input),conf);
final Path outPath = new Path(output);
if(filesystem.exists(outPath)){
filesystem.delete(outPath, true);
}
Job job = new Job(conf,PageRank.class.getSimpleName());
//1.1 读取文件 位置
FileInputFormat.setInputPaths(job, input);
//1.2指定的map类//1.3 map输出的key value 类型 要是和最终的输出类型是一样的 可以省略
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setJarByClass(PageRank.class);
//1.3 分区
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(Reduce.class);
//指定 reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定写出到什么位置
FileOutputFormat.setOutputPath(job, new Path(output));
status = job.waitForCompletion(true);
iteration++;
//输出迭代过程中重要参数到控制台
long count = job.getCounters().findCounter(PageCount.Count).getValue();
long TotalPr = job.getCounters().findCounter(PageCount.TotalPR).getValue();
System.out.println("PageCount:"+count);
System.out.println("TotalPR:"+TotalPr);
double per_pr = TotalPr/(count*1.0d);
System.out.println("PEr_er:"+per_pr);
if((int)per_pr == threshold){
System.out.println("Iteration:"+iteration);
break;
}
}
System.exit(status?0:1);
}
}
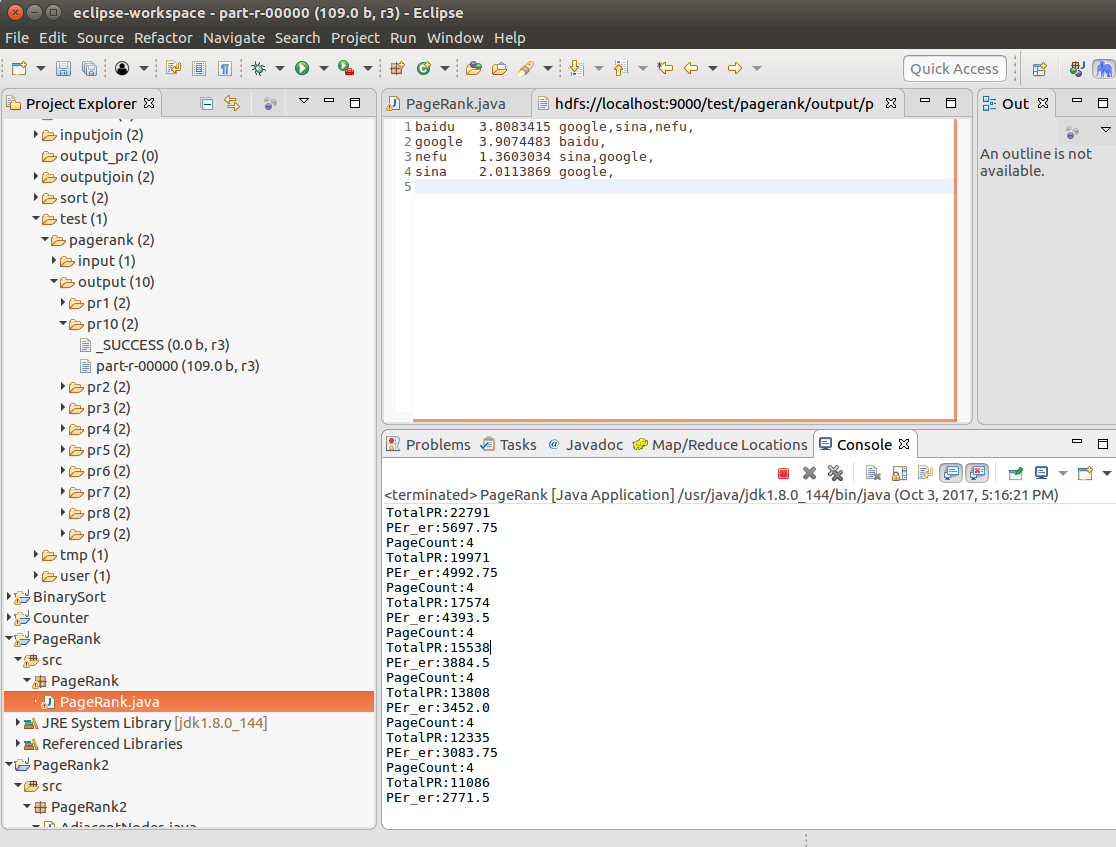
步骤6.点击PageRank.java,Run as->Run on Hadoop运行任务,在DFS Locations下pagerank->output->pr10->part-r-00000查看结果。