实验目的
通过阅读实验原理了解MapReduce的三大高级特性的基础知识,再通过实验了解MapReduce高级特性的具体处理方式。其中,计数器实验目的是统计文件中的不规范字段;排序实验的目的是实现一个二次排序以了解MapReduce的排序实现流程;连接实验的目的是实现一个Reduce端的Join。
实验原理
MapReduce的三大特性包括:计数器,排序和连接(join)。
1、计数器
计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。计数器还可辅助诊断系统故障。如果需要将日志信息传输到map或reduce任务,更好的方法通常是看能否用一个计数器值来记录某一特定事件的发生。对于大型分布式作业而言,使用计数器更为方便。除了因为获取计算器值比输出日志更方便,还有根据计数器值统计特定事件的发生次数要比分析一堆日志文件容易得多。
Hadoop有多个内置计数器:
任务计数器:在任务执行过程中,任务计数器采集任务的相关信息,每个作业的所有任务的结果会被聚集起来。
作业计数器:由YARN的应用宿主维护,因此无需在网络间传输数据,这一点与包括用户自定义的计数器在内的其他计数器不同。这些计数器都是作业级别的统计量,其值不会随着任务运行而改变。
另外,MapReduce允许用户在程序中使用枚举或者字符串的格式类自定义计数器,一个作业可以定义的计数器不限,使用枚举类型时,枚举类型的名称即为组名,枚举类型的字段即为计数器名。计数器是全局的,会跨越所有Mapper和Reducer进行使用,并在作业结束的时候产生一个结果。
2、排序
排序可分为四种排序:普通排序,部分排序,全局排序,二次排序。
普通排序是Mapreduce本身就自带排序功能,Text对象是不适合排序的;IntWritable,LongWritable等实现了WritableComparable类型的对象都是可以排序的;
部分排序指的是map和reduce处理过程中默认包含的对key的排序,如果不要求全排序,可以直接把结果输出,那么每个输出文件中包含的就是安装key执行排序的结果;
Hadoop平台并没有提供全局数据排序,而在大规模数据处理中进行数据的全局排序是非常普遍的需求,使用hadoop进行大量的数据排序最直观的方法是把文件所有内容给map之后,map不做任何处理,直接输出给一个reduce(一个reduce处理的话,不是很适合大规模的数据,效率不高。),利用hadoop自己的shuffle机制,对所有数据进行排序,而后由reduce直接输出,如果要对大规模数据处理中进行数据的全局排序的话,主要思路就是将数据按照区间进行分割,比如对整数排序,[0,10000]的在partition 0中,(10000,20000]在partition 1中,在数据分布均匀的情况下,每个分区内的数据量基本相同,这种就是比较理想的情况了,但是实际中数据往往分布不均匀,出现了数据倾斜的情况,这时按照之前的分区划分数据就不合适了,此时就需要一定的帮助——采样器;
二次排序指的是,有两列数据,第一列相同时,需要对第二列进行排序。
3、连接
MapReduce能够执行大型数据集间的连接操作,除了编写MapReduce程序,还可以考虑采用更高级的框架,如Pig,Hive或Cascading等,它们都将连接操作视为整个实现的核心部分。
假设有两个数据集:气象站数据库和天气记录数据集,并考虑如何合二为一。一个典型的查询是:输出各气象站的历史信息,同时各行记录也包含气象站的元数据信息。
连接操作的具体实现技术取决于数据集的规模及分区方式,如果一个数据集很大而另一个集合很小,以至于可以分发到集群中的每一个节点之中,则可以执行一个MapReduce作业,将各个气象站的天气记录放到一块,从而实现连接。连接操作如果由Mapper执行,则称为“map端连接”,如果由Reducer执行,则称为“reduce端连接”。
如果两个数据集的规模均很大,以至于没有哪个数据集可以被完全复制到集群的每个节点,我们仍然可以使用MapReduce来进行连接。
Map端连接
Map端的连接操作会在数据到达map函数之前执行 ,为了达到这个目的,Map端的输入数据必须:
1.两个数据集被划分为数量相同的分区
2.两个数据集按照相同的键进行排序
由于Map可以设置之前执行的多个作业的输出为其输入,按照以上条件,此时输入数据应该满足:
1.两个作业有相同的reduce数量
2.键是相同的且不可分割
满足Map端连接操作的要求之后,可以利用org.apache.hadoop.mapreduce.join包中的ComsiteInputFormat类在map函数之前执行连接操作。
Reduce端连接
比起Map端,Reduce端的连接对数据的要求没有那么高,利用Shuffle相同键的记录会被输入到同一个reducer(分区)中的特性 ,Reducer端可以天然进行连接操作,但是由于数据要经过Shuffle过程,所以效率往往比Map端的连接要低。而且在Reduce端的连接中,还可以利用到二次排序 。有时候连接需要一个数据集先于另一个数据集到达reduce函数,这时候我们可以利用二次排序对数据的值做一个标号 ,先要达到的数据标号设置为0,另外一个数据集设置为1,然后根据这个标号进行排序就可以实现让想要的数据集先一步到达reduce。
NOTE.本实验中代码前带#的表示shell代码,终端中执行,shell代码的下一行表示该代码的输出;否则为JAVA代码,在eclipse中执行,或普通的文本文件。
实验步骤
1、计数器实验
步骤1.学习计数器的使用。
1、定义计数器
1\)枚举声明计数器// 自定义枚举变量Enum Counter counter = context.getCounter(Enum enum )2\)自定义计数器// 自己命名groupName和counterName Counter counter = context.getCounter(String groupName,String counterName)2、为计数器赋值
1\)初始化计数器 counter.setValue(long value); // 设置初始值2\)计数器自增 counter.increment( long incr); // 增加计数3、获取计数器的值
1\) 获取枚举计数器的值Configuration conf = new Configuration(); Job job = new Job(conf, "MyCounter"); job.waitForCompletion(true); Counters counters=job.getCounters(); Counter counter=counters.findCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_LONG); // 查找枚举计数器,假如Enum的变量为BAD_RECORDS_LONG long value=counter.getValue(); //获取计数值2\) 获取自定义计数器的值Configuration conf = new Configuration(); Job job = new Job(conf, "MyCounter"); job.waitForCompletion(true); Counters counters = job.getCounters(); Counter counter=counters.findCounter("ErrorCounter","toolong"); // 假如groupName为ErrorCounter,counterName为toolong long value = counter.getValue(); // 获取计数值3\) 获取内置计数器的值Configuration conf = new Configuration(); Job job = new Job(conf, "MyCounter"); job.waitForCompletion(true); Counters counters=job.getCounters(); // 查找作业运行启动的reduce个数的计数器,groupName和counterName可以从内置计数器表格查询(前面已经列举有) Counter counter=counters.findCounter("org.apache.hadoop.mapreduce.JobCounter","TOTAL_LAUNCHED_REDUCES");// 假如groupName为org.apache.hadoop.mapreduce.JobCounter,counterName为TOTAL_LAUNCHED_REDUCES long value=counter.getValue();// 获取计数值4) 获取所有计数器的值
Configuration conf = new Configuration(); Job job = new Job(conf, "MyCounter"); Counters counters = job.getCounters(); //遍历计数器 for (CounterGroup group : counters) { for (Counter counter : group) { System.out.println(counter.getDisplayName() + ": " + counter.getName() + ": "+ counter.getValue()); } }
步骤2.打开Hadoop,在当前目录新建文件counter.xml作为输入文件。
#cd /usr/local/hadoop
#sbin/start-dfs.sh
#touch counter.xml
#sudo gedit counter.xml
步骤3.编辑输入文件counter.xml。规定该输入文件中,规范的格式是3个字段,“\t”作为分隔符,其中有2条异常数据,一条数据是只有2个字段,一条数据是有4个字段。其内容如下所示。
hello 1 2
world 2
hadoop 3 4
mapreduce 4 5 6
hdfs 5 6
hive 6 7
步骤4.在eclipse中,选择DFS Locations下localhost的文件夹,右键,新建文件夹counter,然后在终端中将counter.xml存入HDFS。
#bin/hdfs dfs -put counter.xml /counter
步骤5.自定义实现计数器。打开eclipse,在eclipse中File->New->Other->Map/Reduce->Map/Reduce Project,新建项目counter,然后新建包Counter,并新建文件MyCounter.java.
package Counter;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @PackageName Counter
* @ClassName MyCounter
* @Description 规范的格式是3个字段,“\t”作为分隔符,其中有2条异常数据,一条数据是只有2个字段,一条数据是有4个字段
*/
public class MyCounter {
// \t键
private static String TAB_SEPARATOR = "\t";
public static class MyCounterMap extends
Mapper<LongWritable, Text, Text, Text> {
// 定义枚举对象
public static enum LOG_PROCESSOR_COUNTER {
BAD_RECORDS_LONG, BAD_RECORDS_SHORT
};
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String arr_value[] = value.toString().split(TAB_SEPARATOR);
if (arr_value.length > 3) {
/* 自定义计数器 */
context.getCounter("ErrorCounter", "toolong").increment(1);
/* 枚举计数器 */
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_LONG).increment(1);
} else if (arr_value.length < 3) {
// 自定义计数器
context.getCounter("ErrorCounter", "tooshort").increment(1);
// 枚举计数器
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_SHORT).increment(1);
}
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//定义输入路径和输出路径,可以在代码中定义,也可以在Run Configurations中定义,注意要改成自己的HDFS路径
String[] args0 = {
"hdfs://hadoop:9000/counter/counter.xml",
"hdfs://hadoop:9000/counter/out/"
};
// 读取配置文件
Configuration conf = new Configuration();
// 如果输出目录存在,则删除
Path mypath = new Path(args0[1]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
// 新建一个任务
Job job = new Job(conf, "MyCounter");
// 主类
job.setJarByClass(MyCounter.class);
// Mapper
job.setMapperClass(MyCounterMap.class);
// 输入目录
FileInputFormat.addInputPath(job, new Path(args0[0]));
// 输出目录
FileOutputFormat.setOutputPath(job, new Path(args0[1]));
// 提交任务,并退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
步骤6.点击MyCounter.java,Run as->Run on Hadoop运行任务,在Console中查看结果。
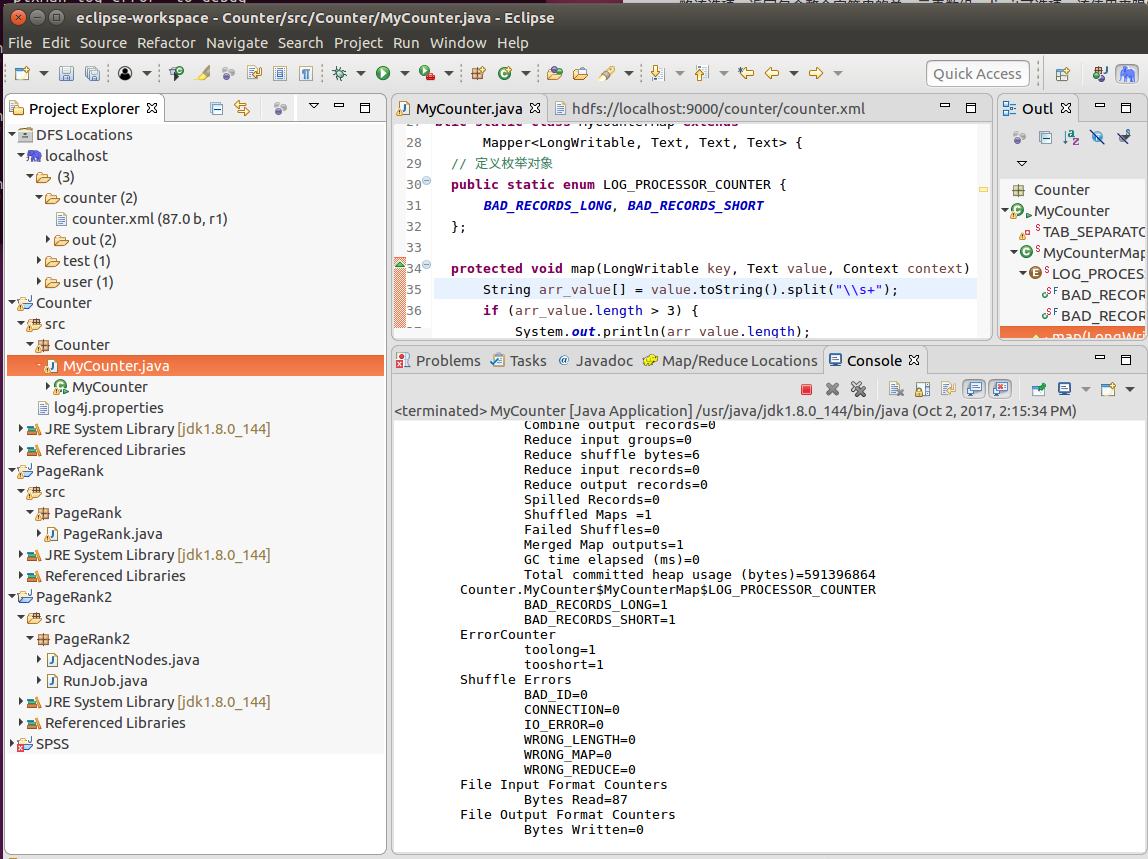 结果即下面:
结果即下面:
ErrorCounter
toolong=1
tooshort=2
com.hadoop.MyCounter$LOG_PROCESSOR_COUNTER
BAD_RECORDS_LONG=1
BAD_RECORDS_SHORT=1
通过枚举声明和自定义计数器两种方式,统计出的不规范数据是一样的。
2.排序实验
步骤1.按照计数器实验的步骤2,打开Hadoop并在当前目录新建并编辑输入文件sort.txt,以tap键作为分隔符。
sort1 1
sort2 3
sort2 77
sort2 54
sort1 2
sort6 22
sort6 221
sort6 20
步骤2.在eclipse中,选择DFS Locations下localhost的文件夹,右键,新建文件夹sort,然后在终端中将sort.txt存入HDFS。
#bin/hdfs dfs -put sort.txt /sort
步骤3.思考具体解决思路。
MapReduce处理数据的大概简单流程:首先,MapReduce框架通过getSplit方法实现对原始文件的切片之后,每一个切片对应着一个map task,inputSplit输入到Map函数进行处理,中间结果经过环形缓冲区的排序,然后分区、自定义二次排序(如果有的话)和合并,再通过shuffle操作将数据传输到reduce task端,reduce端也存在着缓冲区,数据也会在缓冲区和磁盘中进行合并排序等操作,然后对数据按照Key值进行分组,然后每处理完一个分组之后就会去调用一次reduce函数,最终输出结果。
(1)Map端处理:
根据上面的需求,我们要对第一列相同的记录合并,并且对合并后的数字进行排序。而MapReduce框架不管是默认排序或者是自定义排序都只是对Key值进行排序,现在的情况是这些数据不是key值,怎么办?其实我们可以将原始数据的Key值和其对应的数据组合成一个新的Key值,然后新的Key值对应的还是之前的数字。那么我们就可以将原始数据的map输出变成类似下面的数据结构:
{[sort1,1],1}
{[sort2,3],3}
{[sort2,77],77}
{[sort2,54],54}
{[sort1,2],2}
{[sort6,22],22}
{[sort6,221],221}
{[sort6,20],20}
那么我们只需要对[]里面的新key值进行排序就ok了。然后我们需要自定义一个分区处理器,因为我们的目标不是想将新key相同的传到同一个reduce中,而是想将新key中的第一个字段相同的才放到同一个reduce中进行分组合并,所以我们需要根据新key值中的第一个字段来自定义一个分区处理器。通过分区操作后,得到的数据流如下:
Partition1:{[sort1,1],1}、{[sort1,2],2}
Partition2:{[sort2,3],3}、{[sort2,77],77}、{[sort2,54],54}
Partition3:{[sort6,22],22}、{[sort6,221],221}、{[sort6,20],20}
分区操作完成之后,调用自定义排序器对新的Key值进行排序。
{[sort1,1],1}
{[sort1,2],2}
{[sort2,3],3}
{[sort2,54],54}
{[sort2,77],77}
{[sort6,20],20}
{[sort6,22],22}
{[sort6,221],221}
(2)Reduce端处理:
经过Shuffle处理之后,数据传输到Reducer端了。在Reducer端对按照组合键的第一个字段来进行分组,并且每处理完一次分组之后就会调用一次reduce函数来对这个分组进行处理输出。最终的各个分组的数据结构变成类似下面的数据结构:
{sort1,[1,2]}
{sort2,[3,54,77]}
{sort6,[20,22,221]}
步骤4.打开eclipse,在eclipse中File->New->Other->Map/Reduce->Map/Reduce Project,新建项目BinarySort,然后新建包BinarySort,并新建文件CombinationKey .java,实现自定义组合键。
package BinarySort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.Hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义组合键
*/
public class CombinationKey implements WritableComparable<CombinationKey>{
private static final Logger logger = LoggerFactory.getLogger(CombinationKey.class);
private Text firstKey;
private IntWritable secondKey;
public CombinationKey() {
this.firstKey = new Text();
this.secondKey = new IntWritable();
}
public Text getFirstKey() {
return this.firstKey;
}
public void setFirstKey(Text firstKey) {
this.firstKey = firstKey;
}
public IntWritable getSecondKey() {
return this.secondKey;
}
public void setSecondKey(IntWritable secondKey) {
this.secondKey = secondKey;
}
@Override
public void readFields(DataInput dateInput) throws IOException {
// TODO Auto-generated method stub
this.firstKey.readFields(dateInput);
this.secondKey.readFields(dateInput);
}
@Override
public void write(DataOutput outPut) throws IOException {
this.firstKey.write(outPut);
this.secondKey.write(outPut);
}
/**
* 自定义比较策略
* 注意:该比较策略用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,
* 发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整)
*/
@Override
public int compareTo(CombinationKey combinationKey) {
logger.info("-------CombinationKey flag-------");
return this.firstKey.compareTo(combinationKey.getFirstKey());
}
}
PS.在自定义组合键的时候,我们需要特别注意,一定要实现WritableComparable接口,并且实现compareTo方法的比较策略。这个用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整),但是其对我们最终的二次排序结果是没有影响的。我们二次排序的最终结果是由我们的自定义比较器决定的。
步骤5.新建文件DefinedPartition .java,实现自定义分区器
package BinarySort;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义分区
*/
public class DefinedPartition extends Partitioner<CombinationKey,IntWritable>{
private static final Logger logger = LoggerFactory.getLogger(DefinedPartition.class);
/**
* 数据输入来源:map输出
* @param key map输出键值
* @param value map输出value值
* @param numPartitions 分区总数,即reduce task个数
*/
@Override
public int getPartition(CombinationKey key, IntWritable value,int numPartitions) {
logger.info("--------enter DefinedPartition flag--------");
/**
* 注意:这里采用默认的hash分区实现方法
* 根据组合键的第一个值作为分区
* 这里需要说明一下,如果不自定义分区的话,mapreduce框架会根据默认的hash分区方法,
* 将整个组合将相等的分到一个分区中,这样的话显然不是我们要的效果
*/
logger.info("--------out DefinedPartition flag--------");
return (key.getFirstKey().hashCode()&Integer.MAX_VALUE)%numPartitions;
}
}
步骤6.新建文件DefinedComparator .java,实现自定义比较器
package BinarySort;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义二次排序策略
*/
public class DefinedComparator extends WritableComparator {
//输出日志以便分析
private static final Logger logger = LoggerFactory.getLogger(DefinedComparator.class);
public DefinedComparator() {
super(CombinationKey.class,true);
}
@Override
public int compare(WritableComparable combinationKeyOne,
WritableComparable CombinationKeyOther) {
logger.info("---------enter DefinedComparator flag---------");
CombinationKey c1 = (CombinationKey) combinationKeyOne;
CombinationKey c2 = (CombinationKey) CombinationKeyOther;
/**
* 确保进行排序的数据在同一个区内,如果不在同一个区则按照组合键中第一个键排序
* 另外,这个判断是可以调整最终输出的组合键第一个值的排序
* 下面这种比较对第一个字段的排序是升序的,如果想降序则将c1和c2倒过来(假设1)
*/
if(!c1.getFirstKey().equals(c2.getFirstKey())){
logger.info("---------out DefinedComparator flag---------");
return c1.getFirstKey().compareTo(c2.getFirstKey());
}
else{//按照组合键的第二个键的升序排序,将c1和c2倒过来则是按照数字的降序排序(假设2)
logger.info("---------out DefinedComparator flag---------");
return c1.getSecondKey().get()-c2.getSecondKey().get();//0,负数,正数
}
/**
* (1)按照上面的这种实现最终的二次排序结果为:
* sort1 1,2
* sort2 3,54,77
* sort6 20,22,221
* (2)如果实现假设1,则最终的二次排序结果为:
* sort6 20,22,221
* sort2 3,54,77
* sort1 1,2
* (3)如果实现假设2,则最终的二次排序结果为:
* sort1 2,1
* sort2 77,54,3
* sort6 221,22,20
*/
}
}
步骤7.新建文件DefinedGroupSort .java,实现自定义分组策略
package BinarySort;
import org.apache.Hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义分组策略
* 将组合将中第一个值相同的分在一组
*/
public class DefinedGroupSort extends WritableComparator{
private static final Logger logger = LoggerFactory.getLogger(DefinedGroupSort.class);
public DefinedGroupSort() {
super(CombinationKey.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
logger.info("-------enter DefinedGroupSort flag-------");
CombinationKey ck1 = (CombinationKey)a;
CombinationKey ck2 = (CombinationKey)b;
logger.info("-------Grouping result:"+ck1.getFirstKey().
compareTo(ck2.getFirstKey())+"-------");
logger.info("-------out DefinedGroupSort flag-------");
return ck1.getFirstKey().compareTo(ck2.getFirstKey());
}
}
步骤8.新建文件SecondSortMR .java,实现主程序
package com.hadoop;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
*
* 用途说明:二次排序mapreduce
* 需求描述:
* ---------------输入-----------------
* sort1,1
* sort2,3
* sort2,77
* sort2,54
* sort1,2
* sort6,22
* sort6,221
* sort6,20
* ---------------目标输出---------------
* sort1 1,2
* sort2 3,54,77
* sort6 20,22,221
*/
public class SecondSortMR extends Configured implements Tool {
private static final Logger logger = LoggerFactory.getLogger(SecondSortMR.class);
public static class SortMapper extends Mapper<Text, Text, CombinationKey, IntWritable> {
//---------------------------------------------------------
/**
* 这里特别要说明一下,为什么要将这些变量写在map函数外边。
* 对于分布式的程序,我们一定要注意到内存的使用情况,对于mapreduce框架,
* 每一行的原始记录的处理都要调用一次map函数,假设,此个map要处理1亿条输
* 入记录,如果将这些变量都定义在map函数里边则会导致这4个变量的对象句柄编
* 程非常多(极端情况下将产生4*1亿个句柄,当然java也是有自动的gc机制的,
* 一定不会达到这么多),导致栈内存被浪费掉。我们将其写在map函数外边,
* 顶多就只有4个对象句柄。
*/
CombinationKey combinationKey = new CombinationKey();
Text sortName = new Text();
IntWritable score = new IntWritable();
String[] inputString = null;
//---------------------------------------------------------
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
logger.info("---------enter map function flag---------");
//过滤非法记录
if(key == null || value == null || key.toString().equals("")
|| value.equals("")){
return;
}
sortName.set(key.toString());
score.set(Integer.parseInt(value.toString()));
combinationKey.setFirstKey(sortName);
combinationKey.setSecondKey(score);
//map输出
context.write(combinationKey, score);
logger.info("---------out map function flag---------");
}
}
public static class SortReducer extends
Reducer<CombinationKey, IntWritable, Text, Text> {
StringBuffer sb = new StringBuffer();
Text sore = new Text();
/**
* 这里要注意一下reduce的调用时机和次数:reduce每处理一个分组的时候会调用一
* 次reduce函数。也许有人会疑问,分组是什么?看个例子就明白了:
* eg:
* {{sort1,{1,2}},{sort2,{3,54,77}},{sort6,{20,22,221}}}
* 这个数据结果是分组过后的数据结构,那么一个分组分别为{sort1,{1,2}}、
* {sort2,{3,54,77}}、{sort6,{20,22,221}}
*/
@Override
protected void reduce(CombinationKey key,
Iterable<IntWritable> value, Context context)
throws IOException, InterruptedException {
sb.delete(0, sb.length());//先清除上一个组的数据
Iterator<IntWritable> it = value.iterator();
while(it.hasNext()){
sb.append(it.next()+",");
}
//去除最后一个逗号
if(sb.length()>0){
sb.deleteCharAt(sb.length()-1);
}
sore.set(sb.toString());
context.write(key.getFirstKey(),sore);
logger.info("---------enter reduce function flag---------");
logger.info("reduce Input data:{["+key.getFirstKey()+","+
key.getSecondKey()+"],["+sore+"]}");
logger.info("---------out reduce function flag---------");
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf=getConf(); //获得配置文件对象
Job job=new Job(conf,"SoreSort");
job.setJarByClass(SecondSortMR.class);
FileInputFormat.addInputPath(job, new Path(args[0])); //设置map输入文件路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); //设置reduce输出文件路径
job.setMapperClass(SortMapper.class); //设置map函数
job.setReducerClass(SortReducer.class); //设置reduce函数
job.setPartitionerClass(DefinedPartition.class); //设置自定义分区策略
job.setGroupingComparatorClass(DefinedGroupSort.class); //设置自定义分组策略
job.setSortComparatorClass(DefinedComparator.class); //设置自定义二次排序策略
job.setInputFormatClass(KeyValueTextInputFormat.class); //设置文件输入格式
job.setOutputFormatClass(TextOutputFormat.class);//使用默认的output格式
//设置map的输出key和value类型
job.setMapOutputKeyClass(CombinationKey.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce的输出key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
return job.isSuccessful()?0:1;
}
public static void main(String[] args) {
try {
int returnCode = ToolRunner.run(new SecondSortMR(),args);
System.exit(returnCode);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
步骤9.点击SecondSortMR .java,Run as->Run on Hadoop运行任务,在DFS Locations下sort->out->part-r-00000查看结果。查看输出。
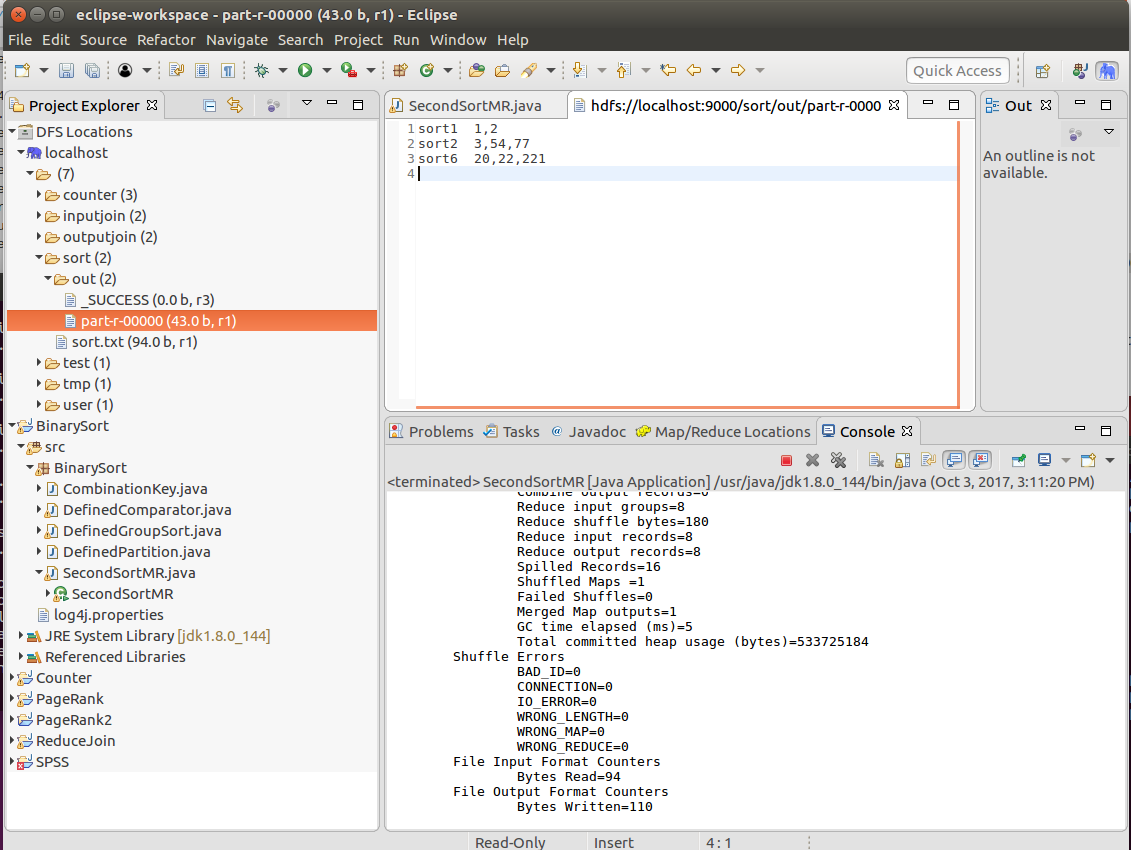
步骤10.通过日志分析过程。
查看控制台中输出的map端和reduce端日志,以验证二次排序的流程,弄清原理。
3、连接实验
步骤1.按照计数器实验的步骤2启动Hadoop,在当前目录新建文件EMP和DEP,分别输入下面两张表的数据,第一行属性名不要,以tap键为分隔符。
Table EMP:(新建文件EMP,第一行属性名不要)
Name Sex Age DepNo
zhang male 20 1
li female 25 2
wang female 30 3
zhou male 35 2
Table Dep:(新建文件DEP,第一行属性名不要)
DepNo DepName
1 Sales
2 Dev
3 Mgt
该实验中,需要执行的连接如下(下面代码仅供描述,不需输入):
select Name,Sex,Age,DepName from EMP inner join DEP on EMP.DepNo=DEP.DepNo
步骤2.在eclipse中,选择DFS Locations下localhost的文件夹,右键,新建文件夹inputjoin,然后在终端中将EMP和DEP存入HDFS。
#bin/hdfs dfs -put EMP /inputjoin
#bin/hdfs dfs -put DEP /inputjoin
步骤3.打开eclipse,在eclipse中File->New->Other->Map/Reduce->Map/Reduce Project,新建项目ReduceJoin,然后新建包Join,并新建文件EmpJoinDep .java和ReduceJoin .java,分别输入下面代码:。
package Join;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class EmpJoinDep implements WritableComparable{
private String Name="";
private String Sex="";
private int Age=0;
private int DepNo=0;
private String DepName="";
private String table="";
public EmpJoinDep() {}
public EmpJoinDep(EmpJoinDep empJoinDep) {
this.Name = empJoinDep.getName();
this.Sex = empJoinDep.getSex();
this.Age = empJoinDep.getAge();
this.DepNo = empJoinDep.getDepNo();
this.DepName = empJoinDep.getDepName();
this.table = empJoinDep.getTable();
}
public String getName() {
return Name;
}
public void setName(String name) {
Name = name;
}
public String getSex() {
return Sex;
}
public void setSex(String sex) {
this.Sex = sex;
}
public int getAge() {
return Age;
}
public void setAge(int age) {
this.Age = age;
}
public int getDepNo() {
return DepNo;
}
public void setDepNo(int depNo) {
DepNo = depNo;
}
public String getDepName() {
return DepName;
}
public void setDepName(String depName) {
DepName = depName;
}
public String getTable() {
return table;
}
public void setTable(String table) {
this.table = table;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(Name);
out.writeUTF(Sex);
out.writeInt(Age);
out.writeInt(DepNo);
out.writeUTF(DepName);
out.writeUTF(table);
}
@Override
public void readFields(DataInput in) throws IOException {
this.Name = in.readUTF();
this.Sex = in.readUTF();
this.Age = in.readInt();
this.DepNo = in.readInt();
this.DepName = in.readUTF();
this.table = in.readUTF();
}
//不做任何排序
@Override
public int compareTo(Object o) {
return 0;
}
@Override
public String toString() {
return "EmpJoinDep [Name=" + Name + ", Sex=" + Sex + ", Age=" + Age
+ ", DepName=" + DepName + "]";
}
}
package Join;
import java.io.IOException;
import java.net.URI;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReduceJoin {
//设置输入和输出路径
private final static String INPUT_PATH = "hdfs://localhost:9000/inputjoin";
private final static String OUTPUT_PATH = "hdfs://localhost:9000/outputmapjoin";
//定义map函数
public static class MyMapper extends Mapper<LongWritable, Text, IntWritable, EmpJoinDep>{
private EmpJoinDep empJoinDep = new EmpJoinDep();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//将文件分隔以数组返回
String[] values = value.toString().split("\\s+");
//如果有4列,即长度为4,则说明是EMP表
if(values.length==4){
empJoinDep.setName(values[0]);
empJoinDep.setSex(values[1]);
empJoinDep.setAge(Integer.parseInt(values[2]));
empJoinDep.setDepNo(Integer.parseInt(values[3]));
empJoinDep.setTable("EMP");
context.write(new IntWritable(Integer.parseInt(values[3])), empJoinDep);
}
//如果长度为2,则是DEP表
if(values.length==2){
empJoinDep.setDepNo(Integer.parseInt(values[0]));
empJoinDep.setDepName(values[1]);
empJoinDep.setTable("DEP");
context.write(new IntWritable(Integer.parseInt(values[0])), empJoinDep);
}
}
}
//定义reduce函数
public static class MyReducer extends Reducer<IntWritable, EmpJoinDep, NullWritable, EmpJoinDep>{
@Override
protected void reduce(IntWritable key, Iterable<EmpJoinDep> values,
Context context)
throws IOException, InterruptedException {
String depName = "";
List<EmpJoinDep> list = new LinkedList<EmpJoinDep>();
//1 emp
//1 dep
for (EmpJoinDep val : values) {
list.add(new EmpJoinDep(val));
//如果是部门表,如果部门编号为1,则获取该部门的名字。
if(val.getTable().equals("DEP")){
depName = val.getDepName();
}
}
//如果上面部门编号是1,则这里也是1。
for (EmpJoinDep listjoin : list) {
//如果是员工表,则需要设置员工的所属部门。
if(listjoin.getTable().equals("EMP")){
listjoin.setDepName(depName);
context.write(NullWritable.get(), listjoin);
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH),conf);
//如果输出目录存在,则删除该目录
if(fileSystem.exists(new Path(OUTPUT_PATH)))
{
fileSystem.delete(new Path(OUTPUT_PATH),true);
}
//设置作业
Job job = Job.getInstance(conf, "Reduce Join");
job.setJarByClass(ReduceJoin.class);
//设置输入
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
//设置map函数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(EmpJoinDep.class);
//设置reduce函数
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(EmpJoinDep.class);
//设置输出
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
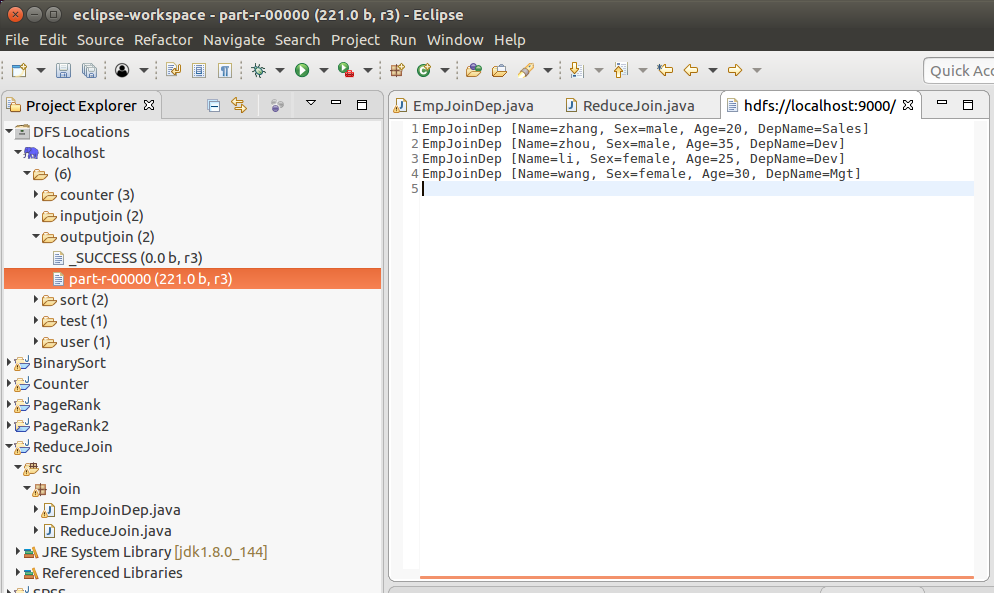
步骤4.点击ReduceJoin .java,Run as->Run on Hadoop运行任务,在DFS Locations下outputjoin->part-r-00000查看结果。查看输出。