实验目的
- 理解HDFS在Hadoop体系结构中的角色。
- 熟练使用HDFS操作常用的Shell命令。
实验原理
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
实验步骤
实验平台
- 操作系统:Ubuntu14.04
- Hadoop版本:2.7.4
- JDK版本:1.8
- IDE:Eclipse
一、向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
1.Shell命令实现
1)先到Hadoop主文件夹
# cd /usr/local/hadoop
2)启动Hadoop服务
# sbin/start-dfs.sh
# sbin/start-yarn.sh
3)创建两个任意文本文件用于实验
# echo "hello world" > local.txt
# echo "hello hadoop" > text.txt
4)创建用户工作目录(HDFS默认工作目录格式为/user/当前用户)
# hadoop fs -mkdir -p /user/当前用户名
5)检查文件是否存在
# hadoop fs -ls

或者使用以下命令
# hadoop fs -test -e text.txt
# echo $?

$?表示shell执行的上一条命令的退出状态值:上一条命令执行成功并退出返回值为0,上一条命令执行失败返回值为1。
6)上传本地文件到HDFS系统
# hadoop fs -put text.txt
7)追加到文件末尾的指令
# hadoop fs -appendToFile local.txt text.txt
8)查看HDFS文件的内容
# hadoop fs -cat text.txt

9)覆盖原有文件的指令(覆盖之后再执行一遍上一步)
# hadoop fs -copyFromLocal -f local.txt text.txt

2.Java实现
1)下载Eclipse的Map/Reduce插件:https://github.com/winghc/hadoop2x-eclipse-plugin
2)解压,将hadoop2x-eclipse-plugin,将hadoop-eclipse-plugin-2.6.0.jar拷贝至Eclipse的plugins目录下,然后重启Eclipse
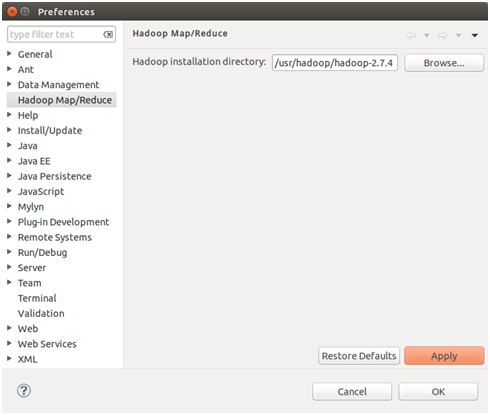
3)打开菜单Window-->Preference-->Hadoop Map/Reduce,配置当前hadoop的安装路径,如图所示:
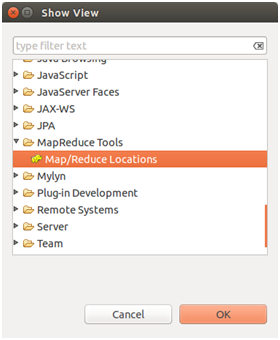
4)开启Eclipse Map/Reduce视图:Window-->Show View-->Other,选择Map/Reduce Tools,如图所示:
5)开启后,在Eclipse的下边栏目中可以看到Map/Reduce的配置:

6)右键点击hadoop,配置hadoop的位置:
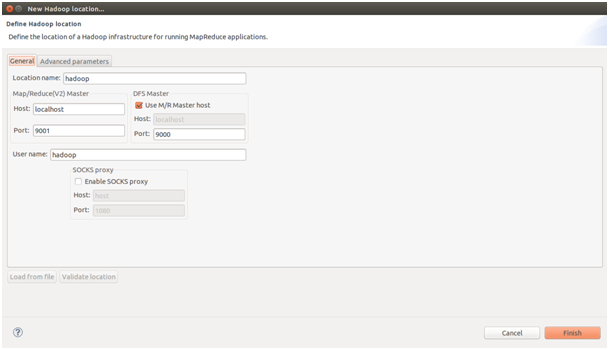
注意:
Map/Reduce Master的配置在${HADOOP_HOME}/etc/hadoop/mapred-site.xml文件中
DFS master的配置在${HADOOP_HOME}/etc/hadoop/core-site.xml文件中
至此,Hadoop Map/Reduce的Eclipse开发环境已经搭建完成。下面开始在Eclipse中创建Map/Reduce项目。
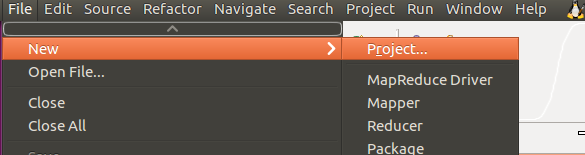
7)首先打开Eclipse,找到 File 菜单,选择 New-->Project
8)选择 Map/Reduce Project,然后Next
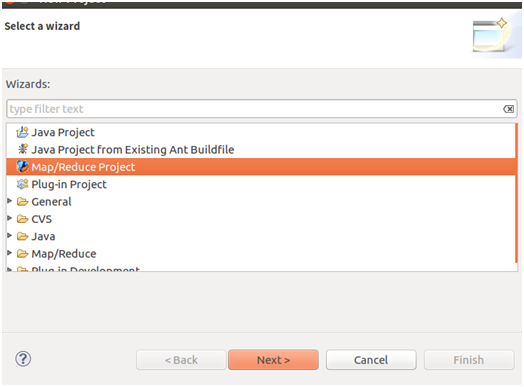
9)输入 Project name,创建Hadoop项目,然后Finish
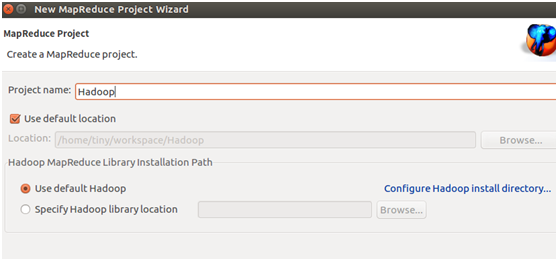
10)点开项目,找到 src 文件夹,右键选择 New -->Class,新建包名为cn.edu.hdfs的HdfsAPI类
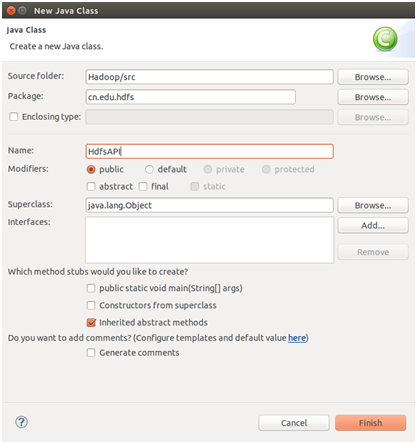
11)写好Java代码,右键选择 Run As -->Run on Hadoop,就可以在Console里看到结果了
package cn.edu.hdfs;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HdfsAPI{
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path) {
try (FileSystem fs = FileSystem.get(conf)) {
return fs.exists(new Path(path));
} catch (IOException e) {
e.printStackTrace();
return false;
}
}
/**
* 复制文件到指定路径 若路径已存在,则进行覆盖
*/
public static void copyFromLocalFile(Configuration conf,
String localFilePath, String remoteFilePath) {
Path localPath = new Path(localFilePath);
Path remotePath = new Path(remoteFilePath);
try (FileSystem fs = FileSystem.get(conf)) {
/* fs.copyFromLocalFile 第一个参数表示是否删除源文件,第二个参数表示是否覆盖 */
fs.copyFromLocalFile(false, true, localPath, remotePath);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 追加文件内容
*/
public static void appendToFile(Configuration conf, String localFilePath,
String remoteFilePath) {
Path remotePath = new Path(remoteFilePath);
try (FileSystem fs = FileSystem.get(conf);
FileInputStream in = new FileInputStream(localFilePath);) {
FSDataOutputStream out = fs.append(remotePath);
byte[] data = new byte[1024];
int read = -1;
while ((read = in.read(data)) > 0) {
out.write(data, 0, read);
}
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 主函数
*/
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String localFilePath = "/usr/hadoop/hadoop-2.7.4/text.txt"; // 本地路径
String remoteFilePath = "/user/text.txt"; // HDFS路径
// String choice = "append"; // 若文件存在则追加到文件末尾
String choice = "overwrite"; // 若文件存在则覆盖
try {
/* 判断文件是否存在 */
boolean fileExists = false;
if (HdfsAPI.test(conf, remoteFilePath)) {
fileExists = true;
System.out.println(remoteFilePath + " 已存在.");
} else {
System.out.println(remoteFilePath + " 不存在.");
}
/* 进行处理 */
if (!fileExists) { // 文件不存在,则上传
HdfsAPI.copyFromLocalFile(conf, localFilePath,
remoteFilePath);
System.out.println(localFilePath + " 已上传至 " + remoteFilePath);
} else if (choice.equals("overwrite")) { // 选择覆盖
HdfsAPI.copyFromLocalFile(conf, localFilePath,
remoteFilePath);
System.out.println(localFilePath + " 已覆盖 " + remoteFilePath);
} else if (choice.equals("append")) { // 选择追加
HdfsAPI.appendToFile(conf, localFilePath,
remoteFilePath);
System.out.println(localFilePath + " 已追加至 " + remoteFilePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果截图:
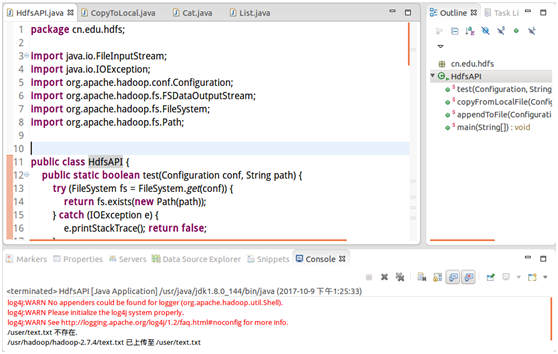
二、显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息。
# hadoop fs -ls -h text.txt

三、给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。
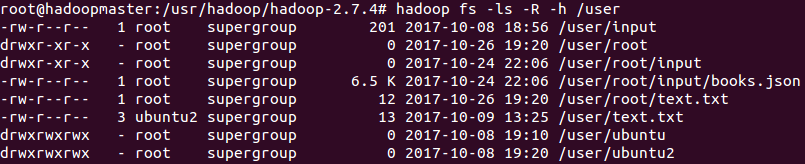
# hadoop fs -ls -R -h /user
四、向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾。
1.追加到文件开头
# hadoop fs -get text.txt
# cat text.txt >> local.txt
# hadoop fs -copyFromLocal -f text.txt text.txt
查看文件内容

2.追加到文件末尾
# hadoop fs -appendToFile local.txt text.txt
再次查看文件内容

五、在HDFS中,将文件从源路径移动到目的路径。
# hadoop fs -mv text.txt input
查看input目录
