实验目的
学会使用Python集成数据
实验原理
数据挖掘需要的数据往往分布在不同的数据源中,数据集成就是将多个数据源合并存放在一个一致的数据存储中。
在R中,数据集成是指将存储在两个数据框中的数据以关键字为依据,以行为单位做列合并,可通过函数merge()实现。
所谓数据集成就是将不同来源的、异质的数据融合到一起。良好的数据融合可以减少数据中的冗余(redundacies)和不一致性(inconsistence),进而提升后续步骤的精度和速度。数据融合包括如下几个步骤:
实体识别问题(Entity Identification Problem)
实体识别中最主要的问题匹配不同的数据源中指向现实世界相同实体的纪录。比如分析有不同销售员纪录的14年和15年两年的销售数据,由于不同的销售员有不同的纪录习惯,顾客的名字纪录方式并不一样,一个销售员喜欢纪录全名(例如 Wardell Stephen Curry II),另外一个销售员喜欢将中间名省略(Wardell S Curry II ),虽然Wardell Stephen Curry II和Wardell S Curry II是现实世界中是同一名顾客,但计算机会识别为两位不同的顾客,解决这个问题就需要Entity Identification。一个常用的Entity Indentification Problem的解决算法是LSH算法
另外一个问题是Schema integration, Schenma在这里指使用DBMS支持的形式化语言对一个数据库的结构化描述,Schema是构建一个数据库的蓝图。Schema intergration则是指,将若干个Schema合成一个global Schema,这个global Schema可以表达所有子Schema的要求(也就是一个总的蓝图)。属性的metadata(比如名称、取值范围、空值处理方法)可以帮助减少Schema Intergration的错误。
冗余和相关性分析
当能够从样本的一个或多个属性推导出另外的属性的时候,那么数据中就存在冗余。检测冗余的一种方法是相关性分析—-给定要进行检测的两个属性,相关性分析可以给出一个属性隐含(imply)另外一个属性的程度。对于标称型(Nominal)数据,可以使用χ2χ2检验,而对于数值数据,可以根据方差和相关系数来分析。
标称数据的χ2χ2相关性检验。
假设有A和B两个属性,A有a1,a2,…aca1,a2,…ac共c种不同的取值,B有b1,b2,…brb1,b2,…br共r种不同的取值。我们可以为属性A和B建立一个列联表(contingency table)C,所谓列联表,就是一个r*c的矩阵,位置(i,j)代表属性A的值aiai和属性B的值bibi在样本中同时出现(事件(A=aiai,B=bjbj)发生)的频率oijoij。属性A和属性B的χ2χ2值可以通过下面的式子计算:
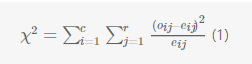
其中oijoij是联合事件(A=aiai,B=bjbj)发生的频率,eijeij是期望频率,用如下的公式计算:
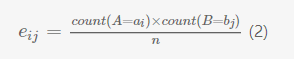
数值数据的相关系数
假设有n个样本,S1,S2,…SnS1,S2,…Sn,样本SiSi的A,B两种属性的值分别是ai,biai,bi,那么属性A和B的相关系数定义是:
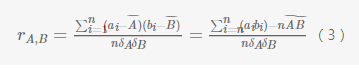
当相关系数是正的时候表示属性A和属性B正相关,当相关系数是负的时候属性A和属性B负相关,注意,相关关系并不等同于因果关系。
实验步骤
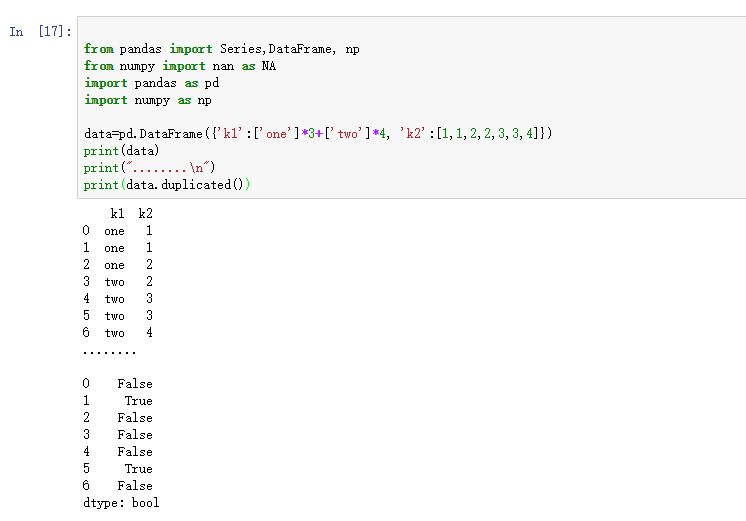
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行。
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- import pandas as pd
- import numpy as np
- data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
- print(data)
- print("........\n")
- print(data.duplicated())
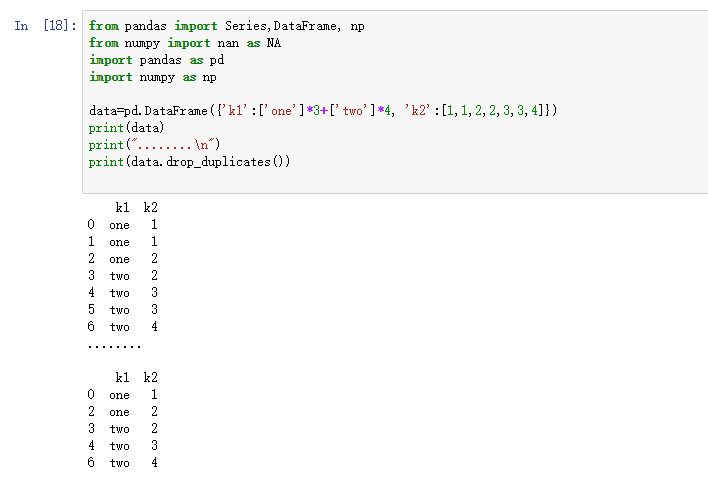
与此相关的还有一个drop_duplicated方法,它用于返回一个移除了重复行的DataFrame:
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- import pandas as pd
- import numpy as np
- data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
- print(data)
- print("........\n")
- print(data.drop_duplicates())
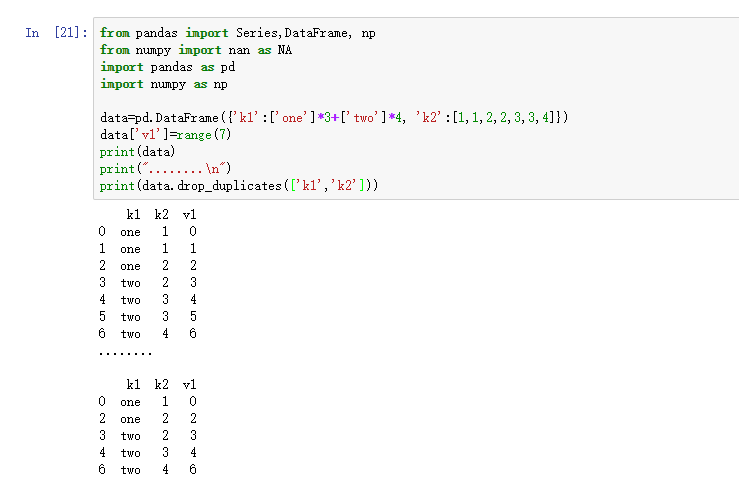
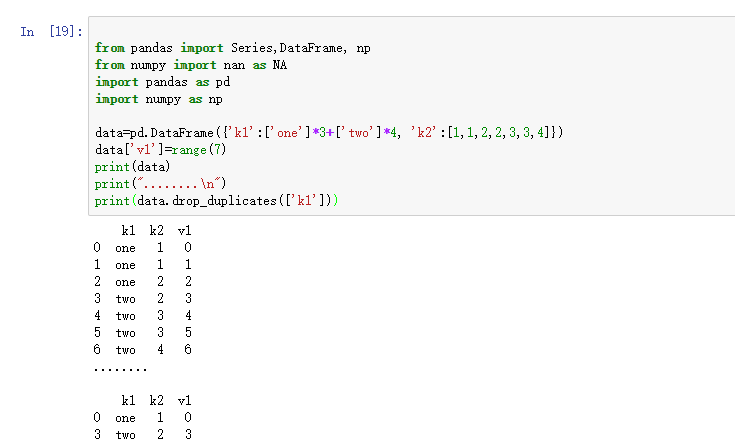
上面的两个方法会默认判断全部列,也可以指定部分列进行重复项判断,假设还有一列值,而只希望根据k1列过滤重复项。
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- import pandas as pd
- import numpy as np
- data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
- data['v1']=range(7)
- print(data)
- print("........\n")
- print(data.drop_duplicates(['k1']))
duplicates和drop_duplicates默认保留第一个出现的值组合。传入take_last=True则保留最后一个:
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- import pandas as pd
- import numpy as np
- data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
- data['v1']=range(7)
- print(data)
- print("........\n")
- print(data.drop_duplicates(['k1','k2'],take_last=True))