实验目的
学会使用Python清洗数据
实验原理
清洗数据主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值、异常值等。
本节教程主要展示如何处理缺失值和异常值。
实验步骤
注意:python2中print语句不加括号,python3中print语句打印内容要加括号!
由于真实世界中的数据来源复杂、体积巨大,往往难以避免地存在缺失、噪声、不一致(inconsistencies)等问题。
当数据的维数过高时还会存在所谓的“维数诅咒(Curse of dimensionality)”问题,过高的维度不仅增加了计算量,反而可能会降低算法的效果。
有些算法对数据存在特殊的要求,比如KNN、Neural Networks、Clustering等基于距离(distance based)的算法在数据进行normalize之后效果会提升。
解决上述问题需要在将数据送入算法之前进行预处理,具体包括Data Cleaning,Data Intergation,Data reduction,Data Transformation and Data Discretization等步骤。下面将对各个部分详细展开。
数据清洗(Data Cleaning)
数据清洗的主要作用是处理数据的某些纪录值缺失,平滑数据中的噪声、发现异常值,改正不一致。
值缺失
针对数据中某些记录的值缺失问题(比如用户销售数据中,有些顾客的收入信息缺失,有些顾客的年龄信息缺失),可以采用如下的方式:
数据缺失在大部分数据分析应用中都很常见,Pandas使用浮点值NaN表示浮点和非浮点数组中的缺失数据,他只是一个便于被检测出来的数据而已。
- from pandas import Series,DataFrame
- string_data=Series(['abcd','efgh','ijkl','mnop'])
- print(string_data)
- print("...........\n")
- print(string_data.isnull())
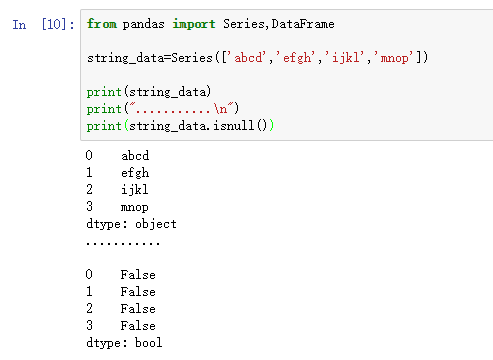
Python内置的None值也会被当作NA处理
- from pandas import Series,DataFrame
- string_data=Series(['abcd','efgh','ijkl','mnop'])
- print(string_data)
- print("...........\n")
- string_data[0]=None
- print(string_data.isnull())
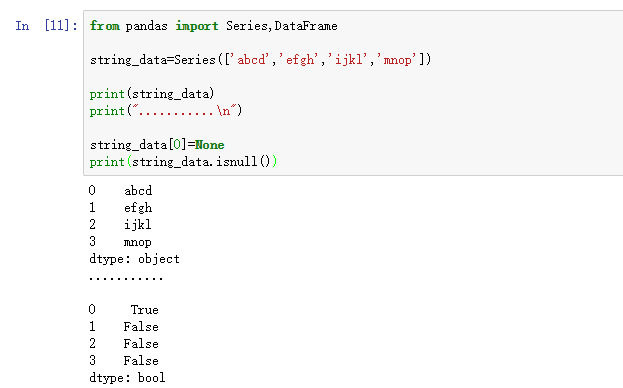
处理NA的方法有四种:dropna,fillna,isnull,notnull
is(not)null,这一对方法对对象做出元素级的应用,然后返回一个布尔型数组,一般可用于布尔型索引。
dropna,对于一个Series,dropna返回一个仅含非空数据和索引值的Series。
问题在于DataFrame的处理方式,因为一旦drop的话,至少要丢掉一行(列)。这里解决方法与前面类似,还是通过一个额外的参数:dropna(axis=0,how=’any’,thresh=None),how参数可选的值为any或者all.all仅在切片元素全为NA时才抛弃该行(列)。thresh为整数类型,eg:thresh=3,那么一行当中至少有三个NA值时才将其保留。
fillna,fillna(value=None,method=None,axis=0)中的value除了基本类型外,还可以使用字典,这样可以实现对不同列填充不同的值。
过滤数据:
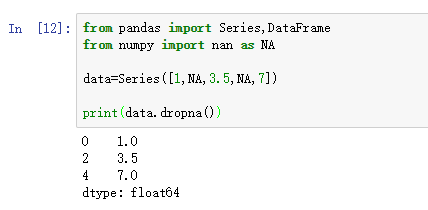
对于一个Series,dropna返回一个仅含非空数据和索引值的Series:
- from pandas import Series,DataFrame
- from numpy import nan as NA
- data=Series([1,NA,3.5,NA,7])
- print(data.dropna()
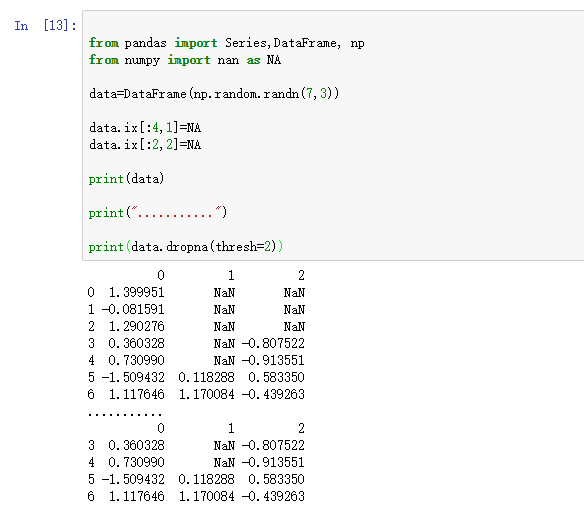
另一个过滤DataFrame行的问题涉及问题序列数据。假设只想留一部分观察数据,可以用thresh参数实现此目的:
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- data=DataFrame(np.random.randn(7,3))
- data.ix[:4,1]=NA
- data.ix[:2,2]=NA
- print(data)
- print("...........")
- print(data.dropna(thresh=2))
不想滤除缺失的数据,而是通过其他方式填补“空洞”,fillna是最主要的函数。
通过一个常数调用fillna就会将缺失值替换为那个常数值:
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- data=DataFrame(np.random.randn(7,3))
- data.ix[:4,1]=NA
- data.ix[:2,2]=NA
- print(data)
- print("...........")
- print(data.fillna(0))
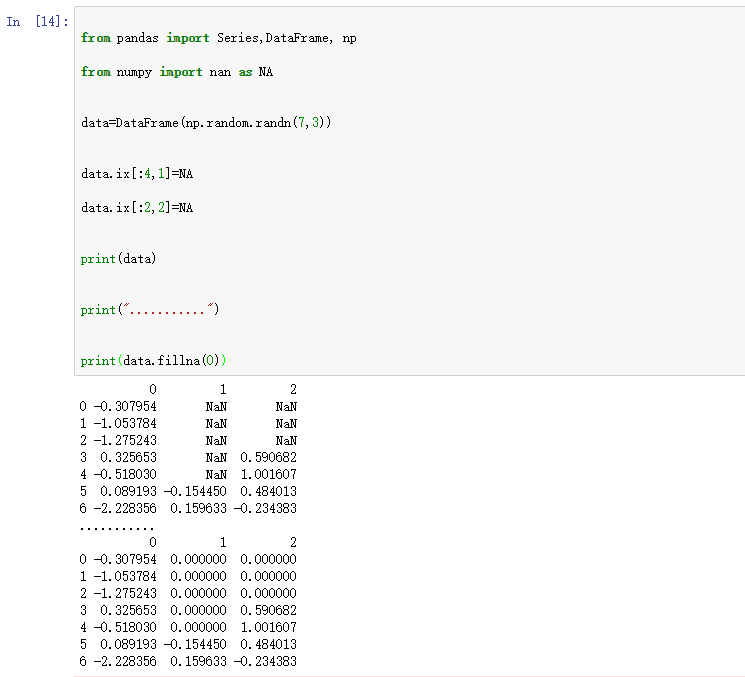
若是通过一个字典调用fillna,就可以实现对不同列填充不同的值。
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- data=DataFrame(np.random.randn(7,3))
- data.ix[:4,1]=NA
- data.ix[:2,2]=NA
- print(data)
- print("...........")
- print(data.fillna({1:111,2:222}))
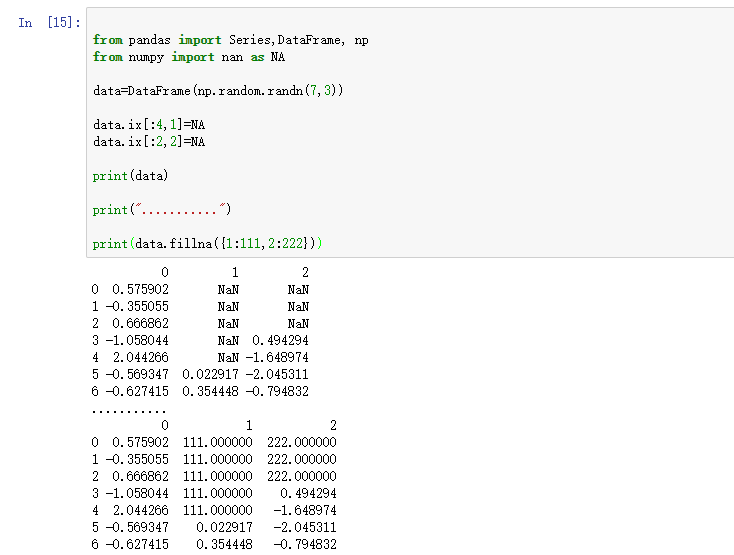
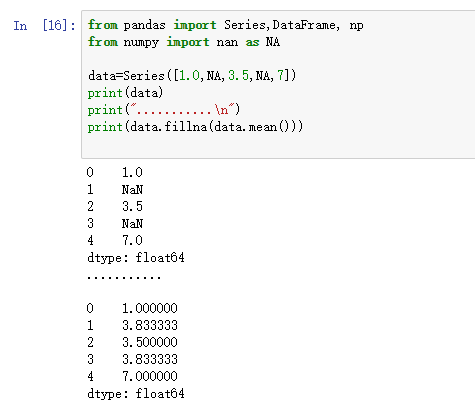
可以利用fillna实现许多别的功能,比如可以传入Series的平均值或中位数:
- from pandas import Series,DataFrame, np
- from numpy import nan as NA
- data=Series([1.0,NA,3.5,NA,7])
- print(data)
- print("...........\n")
- print(data.fillna(data.mean()))
噪声(noise)
噪声是混在观测值的错误(error)或误差(variance),具体去噪方式有以下几种:
Binning。Data Bininig,又称为Bucketing,从字面意思来展开,就是把样本点按照一定的准则分配到不同的bin(bucket)中去,然后对每个样本点根据其所在bin内样本点的分布来赋一个新值,同一个bin的样本点被赋予的新值是一致的。对于一维数据,bin可以按照区间大小划分,也可以按照data frequency来划分,而每个bin的值可以选择分布在其中样本的均值、中值或者边界值。另外,CNN中的max-pooling层,也属于data binning的范畴,典型的max-pooling层bin的尺寸为2*2,选择每个bin中的最大值作为bin四个值的新值。
回归。如果变量之间存在依赖关系,即y=f(x),那么我们可以设法求出依赖关系f,从而根据x来预测y,这也是回归问题的实质。实际中更常见的假设是P(y)=N(f(x)),N是正态分布。假设y是观测值且存在噪声,如果我们能求出x和y之间的依赖关系,从而根据x来更新y的值,就可以去除其中的随机噪声,这就是回归去噪的原理。
异常值检测。数据中的噪声可能有两种,一种是随机误差,另外一种可能是错误,比如我们手上有一份顾客的身高数据,其中某一位顾客的身高纪录是20m,很明显,这是一个错误,如果这个一场的样本进入了我们训练数据可能会对结果产生很大影响,这也是去噪中使用异常值检测的意义所在。当然,异常值检测远不止去噪这么一个应用,网络入侵检测、视频中行人异常行为检测、欺诈检测等都是异常值检测的应用。异常值检测方法也分为有监督,无监督和半监督方法,这里不再详细展开。