神经网络分类算法
一 实验目的
- 了解感知机的原理
- 了解通过感知机如何组合成神经网络
- 学会使用Pyhton工具建立神经网络分类模型
二 实验原理
人工神经网络(ANN),简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。
人工神经网络从以下四个方面去模拟人的智能行为:
- 物理结构:人工神经元将模拟生物神经元的功能
- 计算模拟:人脑的神经元有局部计算和存储的功能,通过连接构成一个系统。人工神经网络中也有大量有局部处理能力的神经元,也能够将信息进行大规模并行处理
- 存储与操作:人脑和人工神经网络都是通过神经元的连接强度来实现记忆存储功能,同时为概括、类比、推广提供有力的支持
训练:同人脑一样,人工神经网络将根据自己的结构特性,使用不同的训练、学习过程,自动从实践中获得相关知识
神经网络是一种运算模型,由大量的节点(或称“神经元”,或“单元”)和之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
感知器
历史上,科学家一直希望模拟人的大脑,造出可以思考的机器。人为什么能够思考?科学家发现,原因在于人体的神经网络。
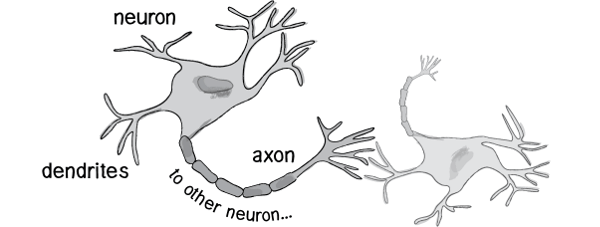
- 外部刺激通过神经末梢,转化为电信号,转导到神经细胞(又叫神经元)。
- 无数神经元构成神经中枢。
- 神经中枢综合各种信号,做出判断
- 人体根据神经中枢的指令,对外部刺激做出反应。
既然思考的基础是神经元,如果能够"人造神经元"(artificial neuron),就能组成人工神经网络,模拟思考。上个世纪六十年代,提出了最早的"人造神经元"模型,叫做"感知器"(perceptron),直到今天还在用。
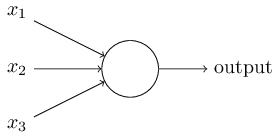
上图的圆圈就代表一个感知器。它接受多个输入(x1,x2,x3...),产生一个输出(output),好比神经末梢感受各种外部环境的变化,最后产生电信号。
为了简化模型,我们约定每种输入只有两种可能:1 或 0。如果所有输入都是1,表示各种条件都成立,输出就是1;如果所有输入都是0,表示条件都不成立,输出就是0
决策模型
单个的感知器构成了一个简单的决策模型,已经可以拿来用了。真实世界中,实际的决策模型则要复杂得多,是由多个感知器组成的多层网络。
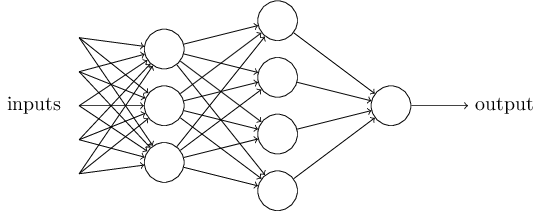
上图中,底层感知器接收外部输入,做出判断以后,再发出信号,作为上层感知器的输入,直至得到最后的结果。(注意:感知器的输出依然只有一个,但是可以发送给多个目标。)
一个神经网络的搭建,需要满足三个条件。
输入和输出
权重(W)和阈值(b)
多层感知机的结构
神经网络的运作过程如下:
确定输入和输出
- 找到一种或多种算法,可以从输入得到输出
- 找到一组已知答案的数据集,用来训练模型,估算W和b
- 一旦新的数据产生,输入模型,就可以得到结果,同时对W和b进行校正
可以看到,整个过程需要海量计算。所以,神经网络直到最近这几年才有实用价值,而且一般的 CPU 还不行,要使用专门为机器学习定制的 GPU 来计算。
三 实验步骤
MLPClassifier类使用反向传播算法实现了多层感知机算法。其简单实现如下:
>>> from sklearn.neural_network import MLPClassifier
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
... hidden_layer_sizes=(5, 2), random_state=1)
...
>>> clf.fit(X, y)
MLPClassifier(activation='relu', alpha=1e-05, batch_size='auto',
beta_1=0.9, beta_2=0.999, early_stopping=False,
epsilon=1e-08, hidden_layer_sizes=(5, 2), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
nesterovs_momentum=True, power_t=0.5, random_state=1, shuffle=True,
solver='lbfgs', tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
模型训练之后,就可以用来预测新的样本所属类别:
>>> clf.predict([[2., 2.], [-1., -2.]])
array([1, 0])
MLP可以在训练集上训练出非线性模型,clf.coefs_包含了模型参数的权重信息:
>>> [coef.shape for coef in clf.coefs_]
[(2, 5), (5, 2), (2, 1)]
目前,MLPClassifier仅支持交叉熵损失函数,通过运行predict_proba方法可以进行概率估计。
MLP使用反向传播训练。 更准确地说,它使用某种形式的梯度下降训练,并且使用反向传播计算梯度。 对于分类,它最小化交叉熵损失函数,给出每个样本x的概率估计P(y | x)向量x:
>>> clf.predict_proba([[2., 2.], [1., 2.]])
array([[ 1.967...e-04, 9.998...-01],
[ 1.967...e-04, 9.998...-01]])
MLPClassifier通过应用Softmax作为输出功能支持多类分类。
此外,该模型支持多标签分类,其中样本可以属于多个类。 对于每个类,原始输出通过逻辑函数。 大于或等于0.5的值将舍入为1,否则为0.对于样本的预测输出,值为1的索引表示该样本的分配类别:
>>> X = [[0., 0.], [1., 1.]]
>>> y = [[0, 1], [1, 1]]
>>> clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
... hidden_layer_sizes=(15,), random_state=1)
...
>>> clf.fit(X, y)
MLPClassifier(activation='relu', alpha=1e-05, batch_size='auto',
beta_1=0.9, beta_2=0.999, early_stopping=False,
epsilon=1e-08, hidden_layer_sizes=(15,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
nesterovs_momentum=True, power_t=0.5, random_state=1, shuffle=True,
solver='lbfgs', tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
>>> clf.predict([[1., 2.]])
array([[1, 1]])
>>> clf.predict([[0., 0.]])
array([[0, 1]])
以下是在鸢尾花数据集上的实例:
print(__doc__)
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn import datasets
# different learning rate schedules and momentum parameters
params = [{'solver': 'sgd', 'learning_rate': 'constant', 'momentum': 0,
'learning_rate_init': 0.2},
{'solver': 'sgd', 'learning_rate': 'constant', 'momentum': .9,
'nesterovs_momentum': False, 'learning_rate_init': 0.2},
{'solver': 'sgd', 'learning_rate': 'constant', 'momentum': .9,
'nesterovs_momentum': True, 'learning_rate_init': 0.2},
{'solver': 'sgd', 'learning_rate': 'invscaling', 'momentum': 0,
'learning_rate_init': 0.2},
{'solver': 'sgd', 'learning_rate': 'invscaling', 'momentum': .9,
'nesterovs_momentum': True, 'learning_rate_init': 0.2},
{'solver': 'sgd', 'learning_rate': 'invscaling', 'momentum': .9,
'nesterovs_momentum': False, 'learning_rate_init': 0.2},
{'solver': 'adam', 'learning_rate_init': 0.01}]
labels = ["constant learning-rate", "constant with momentum",
"constant with Nesterov's momentum",
"inv-scaling learning-rate", "inv-scaling with momentum",
"inv-scaling with Nesterov's momentum", "adam"]
plot_args = [{'c': 'red', 'linestyle': '-'},
{'c': 'green', 'linestyle': '-'},
{'c': 'blue', 'linestyle': '-'},
{'c': 'red', 'linestyle': '--'},
{'c': 'green', 'linestyle': '--'},
{'c': 'blue', 'linestyle': '--'},
{'c': 'black', 'linestyle': '-'}]
def plot_on_dataset(X, y, ax, name):
# for each dataset, plot learning for each learning strategy
print("\nlearning on dataset %s" % name)
ax.set_title(name)
X = MinMaxScaler().fit_transform(X)
mlps = []
if name == "digits":
# digits is larger but converges fairly quickly
max_iter = 15
else:
max_iter = 400
for label, param in zip(labels, params):
print("training: %s" % label)
mlp = MLPClassifier(verbose=0, random_state=0,
max_iter=max_iter, **param)
mlp.fit(X, y)
mlps.append(mlp)
print("Training set score: %f" % mlp.score(X, y))
print("Training set loss: %f" % mlp.loss_)
for mlp, label, args in zip(mlps, labels, plot_args):
ax.plot(mlp.loss_curve_, label=label, **args)
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# load / generate some toy datasets
iris = datasets.load_iris()
digits = datasets.load_digits()
data_sets = [(iris.data, iris.target),
(digits.data, digits.target),
datasets.make_circles(noise=0.2, factor=0.5, random_state=1),
datasets.make_moons(noise=0.3, random_state=0)]
for ax, data, name in zip(axes.ravel(), data_sets, ['iris', 'digits',
'circles', 'moons']):
plot_on_dataset(*data, ax=ax, name=name)
fig.legend(ax.get_lines(), labels=labels, ncol=3, loc="upper center")
plt.show()
输出结果:
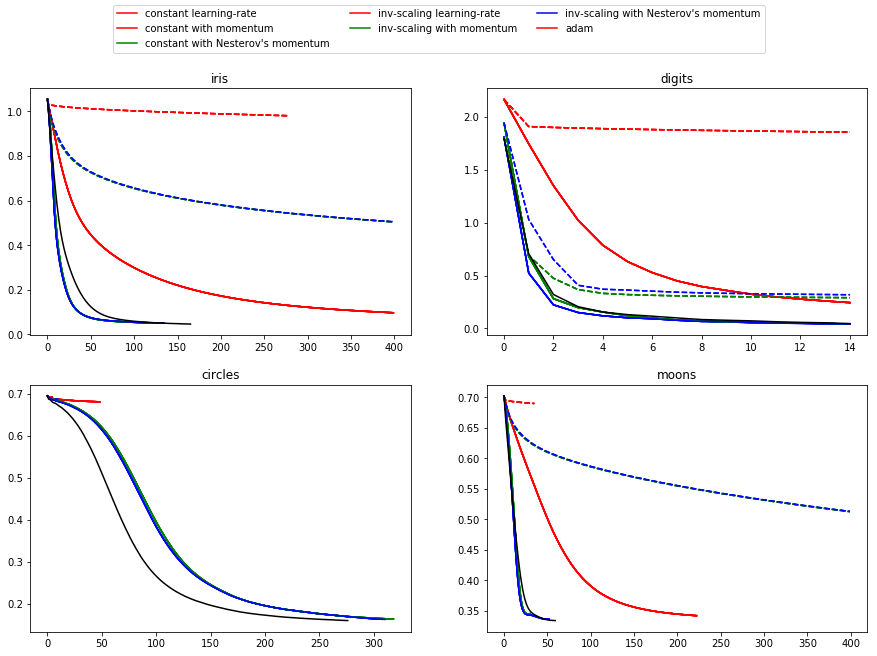
learning on dataset iris
training: constant learning-rate
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\neural_network\multilayer_perceptron.py:563: ConvergenceWarning: Stochastic Optimizer: Maximum iterations reached and the optimization hasn't converged yet.
% (), ConvergenceWarning)
Training set score: 0.980000
Training set loss: 0.096922
training: constant with momentum
Training set score: 0.980000
Training set loss: 0.050260
training: constant with Nesterov's momentum
Training set score: 0.980000
Training set loss: 0.050277
training: inv-scaling learning-rate
Training set score: 0.360000
Training set loss: 0.979983
training: inv-scaling with momentum
Training set score: 0.860000
Training set loss: 0.504017
training: inv-scaling with Nesterov's momentum
Training set score: 0.860000
Training set loss: 0.504760
training: adam
Training set score: 0.980000
Training set loss: 0.046248
learning on dataset digits
training: constant learning-rate
Training set score: 0.956038
Training set loss: 0.243802
training: constant with momentum
Training set score: 0.992766
Training set loss: 0.041297
training: constant with Nesterov's momentum
Training set score: 0.993879
Training set loss: 0.042898
training: inv-scaling learning-rate
Training set score: 0.638843
Training set loss: 1.855465
training: inv-scaling with momentum
Training set score: 0.912632
Training set loss: 0.290584
training: inv-scaling with Nesterov's momentum
Training set score: 0.909293
Training set loss: 0.318387
training: adam
Training set score: 0.991653
Training set loss: 0.045934
learning on dataset circles
training: constant learning-rate
Training set score: 0.830000
Training set loss: 0.681498
training: constant with momentum
Training set score: 0.940000
Training set loss: 0.163712
training: constant with Nesterov's momentum
Training set score: 0.940000
Training set loss: 0.163012
training: inv-scaling learning-rate
Training set score: 0.500000
Training set loss: 0.692855
training: inv-scaling with momentum
Training set score: 0.510000
Training set loss: 0.688376
training: inv-scaling with Nesterov's momentum
Training set score: 0.500000
Training set loss: 0.688593
training: adam
Training set score: 0.930000
Training set loss: 0.159988
learning on dataset moons
training: constant learning-rate
Training set score: 0.850000
Training set loss: 0.342245
training: constant with momentum
Training set score: 0.850000
Training set loss: 0.345580
training: constant with Nesterov's momentum
Training set score: 0.850000
Training set loss: 0.336284
training: inv-scaling learning-rate
Training set score: 0.500000
Training set loss: 0.689729
training: inv-scaling with momentum
Training set score: 0.830000
Training set loss: 0.512595
training: inv-scaling with Nesterov's momentum
Training set score: 0.830000
Training set loss: 0.513034
training: adam
Training set score: 0.850000
Training set loss: 0.334243
四 常见问题
多层感知机如何解决回归问题?
多层感知机最初是为了做分类的,但是它也可以处理回归问题,只要在最后将softmax等分类器改成sigmoid回归就行。多层感知机的隐层作用?
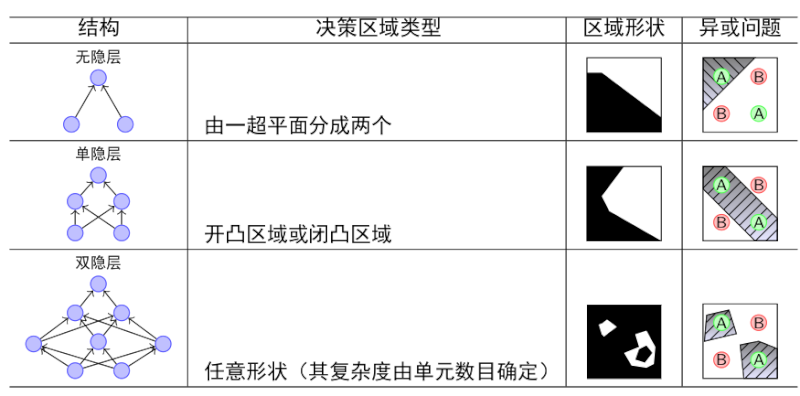
MLP的缺陷?
1.网络的隐含节点个数选取问题至今仍是一个世界难题(Google,
Elsevier, CNKI);2.停止阈值、学习率、动量常数需要采用”trial-and-error”法,极其耗时(动手实验);
3.学习速度慢;
4.容易陷入局部极值,学习不够充分。