作业26
练习1 数据导入
1.将数据集的csv文件导入
mydata <- read.csv("http://stats.idre.ucla.edu/stat/data/binary.csv")
练习2 查看数据
1.查看数据集的第一列
mydata[,1]
[1] 0 1 1 1 0 1 1 0 1 0 0 0 1 0 1 0 0 0 0 1 0 1 0 0 1 1 1 1 1 0 0 0 0 1 0 0 0 0 1 1 0
[42] 1 1 0 0 1 1 0 0 0 0 0 0 1 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0
[83] 0 0 1 0 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 1 0 1 0 1 1 0
[124] 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 1 0 1 0 1 0 0 1 0 1 0 0 0 0 1 0
[165] 0 0 0 0 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 1 1 0 1
[206] 1 0 1 0 0 0 0 0 0 1 1 0 1 0 1 0 0 1 0 0 1 0 0 0 1 0 0 0 0 1 0 1 0 0 0 0 1 1 0 0 0
[247] 0 0 0 0 0 0 1 1 1 0 1 1 0 0 0 0 1 1 1 0 0 1 1 0 1 0 1 0 0 1 0 1 1 1 0 0 0 0 1 0 1
[288] 1 0 0 1 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 1 0 0 0 0 0 0 1 0 1 1 1 1 0 0 0 0 0 0 0 0 1
[329] 0 0 0 0 0 0 1 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 1 0 1 1 0 0 1 0 1 1 0 0 1 0 0 0 0
[370] 0 1 1 1 1 0 0 0 1 0 0 0 1 0 0 1 0 1 0 0 0 1 1 1 1 1 0 0 0 0 0
2.查看数据集的变量名
str(mydata)
'data.frame': 400 obs. of 4 variables:
$ admit: int 0 1 1 1 0 1 1 0 1 0 ...
$ gre : int 380 660 800 640 520 760 560 400 540 700 ...
$ gpa : num 3.61 3.67 4 3.19 2.93 3 2.98 3.08 3.39 3.92 ...
$ rank : Factor w/ 4 levels "1","2","3","4": 3 3 1 4 4 2 1 2 3 2 ...
练习3 数据操作
1.计算数据中各属性的标准差
sapply(mydata, sd)
## admit gre gpa rank
## 0.466 115.517 0.381 0.944
2.计算预测值的模型是否比仅仅含有截距的模型(即,空模型)的偏差
with(mylogit, null.deviance - deviance)
## [1] 41.5
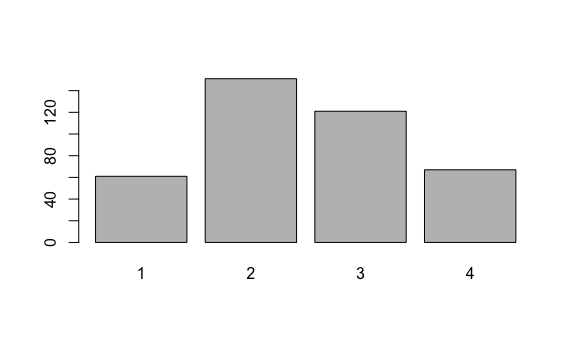
练习4 图形绘制操作
- 画出数据中rank各值出现频数的柱状图
barplot(table(mydata$rank))