实验目的
学会使用R进行数据规约
实验原理
在大数据集上进行复杂的数据分析将需要很长的时间,数据规约可以产生更小的但保持原数据完整行的新数据及,在规约后的数据集上进行分析和挖掘将更有效率。
实验步骤
数据规约的意义在于:
- 降低无效、错误数据对建模的影响,提高建模的准确性;
- 少量且具有代表性的数据将大幅度缩减数据挖掘所需的时间;
- 降低存储数据的成本。
属性规约通过属性合并来创建新属性维数,或者直接通过删除不相关的属性来减少数据维数,从而提高数据挖掘的效率、降低计算成本。常用地数据规约方法有合并属性、逐步向前选择、逐步向后删除、主成分分析等等,本教程主要介绍主成分分析。
主成分分析(PCA)的目标是用一组较少的不相关变量代替大量相关变量,同时尽可能保留初始变量的信息,这些推导所得的变量称为主成分,它们是观测变量的线性组合。下面使用R中的数据集USArrests展示主成分分析。
> install.packages("graphics")
> library(graphics)
> princomp(USArrests, cor = TRUE)
Call:
princomp(x = USArrests, cor = TRUE)
Standard deviations:
Comp.1 Comp.2 Comp.3 Comp.4
1.5748783 0.9948694 0.5971291 0.4164494
4 variables and 50 observations.
> summary(pc.cr <- princomp(USArrests, cor = TRUE))
Importance of components:
Comp.1 Comp.2 Comp.3 Comp.4
Standard deviation 1.5748783 0.9948694 0.5971291 0.41644938
Proportion of Variance 0.6200604 0.2474413 0.0891408 0.04335752
Cumulative Proportion 0.6200604 0.8675017 0.9566425 1.00000000
> loadings(pc.cr)
Loadings:
Comp.1 Comp.2 Comp.3 Comp.4
Murder -0.536 0.418 -0.341 0.649
Assault -0.583 0.188 -0.268 -0.743
UrbanPop -0.278 -0.873 -0.378 0.134
Rape -0.543 -0.167 0.818
Comp.1 Comp.2 Comp.3 Comp.4
SS loadings 1.00 1.00 1.00 1.00
Proportion Var 0.25 0.25 0.25 0.25
Cumulative Var 0.25 0.50 0.75 1.00
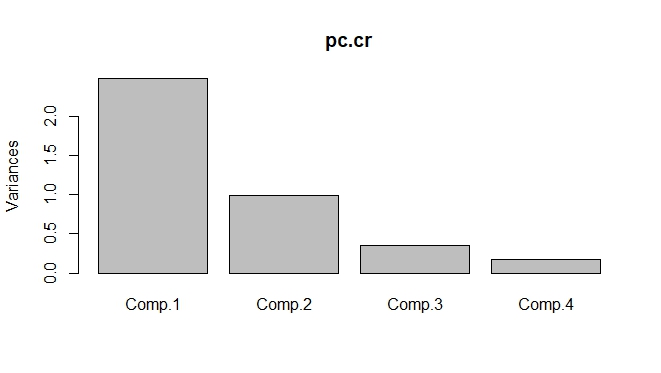
> screeplot(pc.cr)