实验目的
熟悉HBase过滤器的使用操作。
实验原理
HBase为筛选数据提供了一组过滤器,通过这个过滤器可以在HBase中的数据的多个维度(行、列、数据版本)上进行对数据的筛选操作,也就是说过滤器最终能够筛选的数据能够细化到具体的一个存储单元格上(由行键、列名、时间戳定位)。通常来说,通过行键、值来筛选数据的应用场景较多。
过滤器的操作符
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP no operation
过滤器的比较器
BinaryComparator 按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator 跟前面相同,只是比较左端的数据是否相同
NullComparator 判断给定的是否为空
BitComparator 按位比较 a BitwiseOp class 做异或,与,并操作
RegexStringComparator 提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator 判断提供的子串是否出现在table的value中。
实验步骤
一、RowFilter
构造函数:
public RowFilter(org.apache.hadoop.hbase.filter.CompareFilter.CompareOp rowCompareOp, org.apache.hadoop.hbase.filter.WritableByteArrayComparable rowComparator) {}
//选择比较RowKey来确认返回讯息
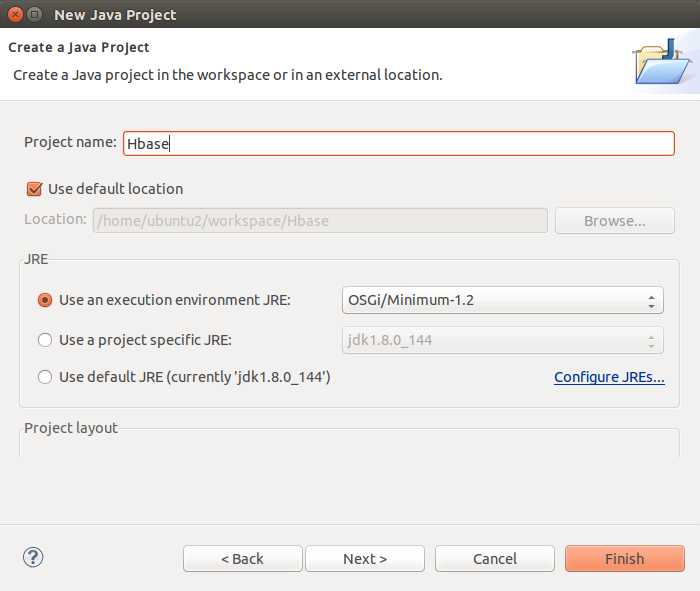
1.在Eclipse中创建项目Hbase
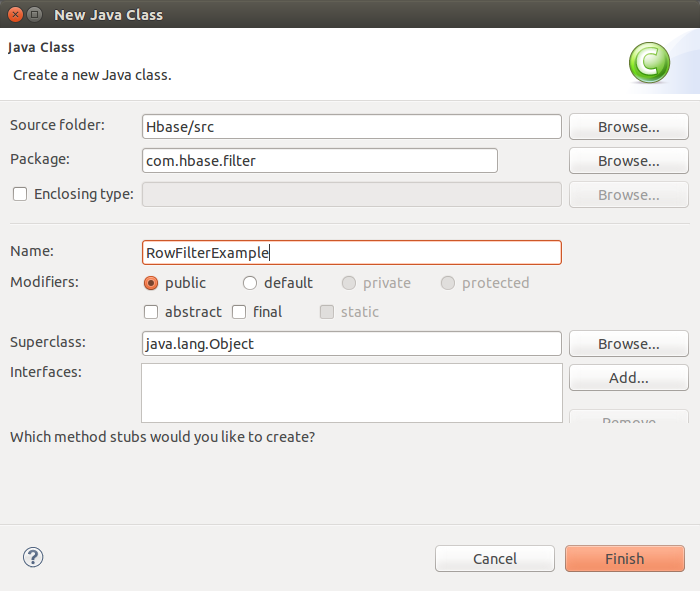
2.新建一个com.hbase.filter包,并创建RowFilterExample 类
3.下载Hbase相关的jar包:http://download.csdn.net/download/xiexueshi/9463105,在项目根目录下创建一个文件夹lib,把Hbase相关的jar包复制到该文件夹中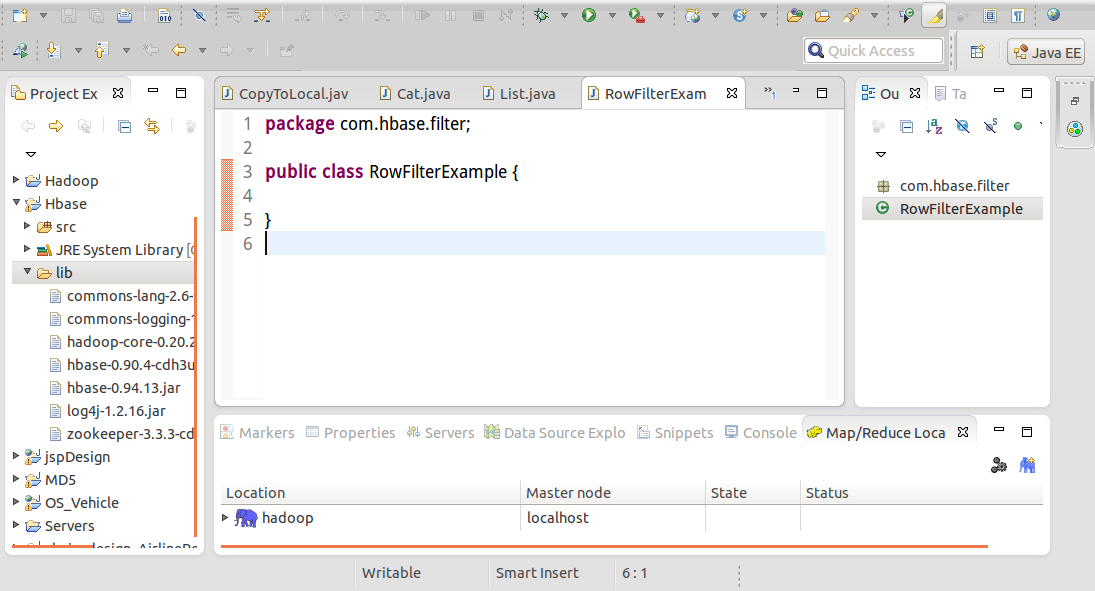 4.将lib下所有的jar包导入到项目环境中,首先全选lib文件夹下的jar包文件,单击右键,选择“Build Path”-->“Add to Build Path”
4.将lib下所有的jar包导入到项目环境中,首先全选lib文件夹下的jar包文件,单击右键,选择“Build Path”-->“Add to Build Path”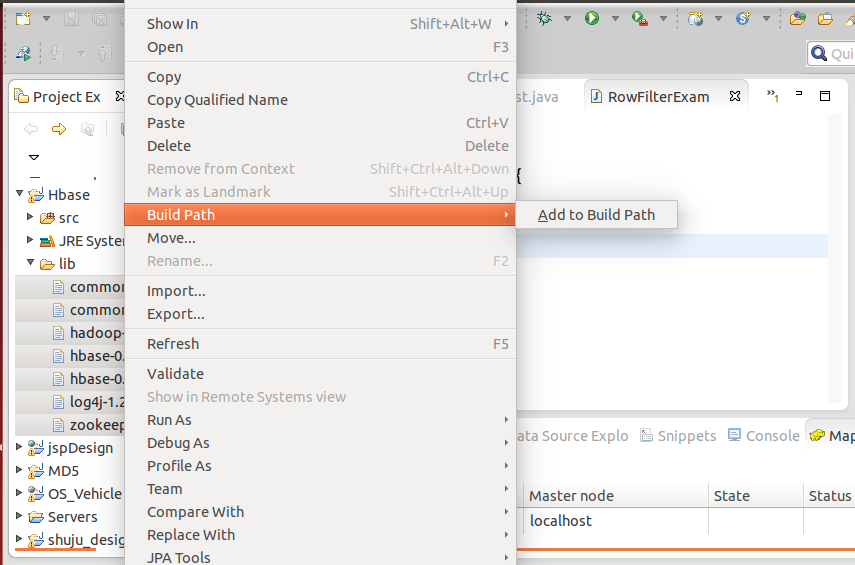 5.创建程序入口main方法,代码如下:
5.创建程序入口main方法,代码如下:
package com.hbase.filter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.util.Bytes;
public class RowFilterExample {
public static void main(String[] args) throws IOException {
//配置文件设置
//创建用于客户端的配置类实例
Configuration conf = HBaseConfiguration.create();
//设置连接Zookeeper的地址
//hbase客户端连接的是Zookeeper
conf.set("hbase.zookeeper.quorum", "QT-H-0038");
HBaseHelper helper = HBaseHelper.getHelper(conf);
helper.dropTable("testtable");
helper.createTable("testtable", "colfam1", "colfam2");
System.out.println("Adding rows to table...");
helper.fillTable("testtable", 1, 100, 100, "colfam1", "colfam2");
//获得要操作的表对象
//"conf"为配置文件,"testtable"为数据库中的表名
HTable table = new HTable(conf, "testtable");
//创建Scan对象
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("colfam1"), Bytes.toBytes("col-0"));
//设置过滤器,“CompareOp”表示小于或等于
Filter filter1 = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL,
new BinaryComparator(Bytes.toBytes("row-22")));
//将过滤器设置给Scan对象
scan.setFilter(filter1);
//获得查询结果
ResultScanner scanner1 = table.getScanner(scan);
System.out.println("Scanning table #1...");
//遍历结果
for (Result res : scanner1) {
System.out.println(res);
}
//释放ResultScanner资源
scanner1.close();
//设置过滤器,“CompareOp”表示小于或等于,第二个参数为正则表达式
Filter filter2 = new RowFilter(CompareFilter.CompareOp.EQUAL,
new RegexStringComparator(".*-.5"));
//将过滤器设置给Scan对象
scan.setFilter(filter2);
//获得查询结果
ResultScanner scanner2 = table.getScanner(scan);
System.out.println("Scanning table #2...");
//遍历结果
for (Result res : scanner2) {
System.out.println(res);
}
//释放ResultScanner资源
scanner2.close();
//设置过滤器,“CompareOp”表示小于或等于
Filter filter3 = new RowFilter(CompareFilter.CompareOp.EQUAL,
new SubstringComparator("-5"));
//将过滤器设置给Scan对象
scan.setFilter(filter3);
//获得查询结果
ResultScanner scanner3 = table.getScanner(scan);
System.out.println("Scanning table #3...");
//遍历结果
for (Result res : scanner3) {
System.out.println(res);
}
//释放ResultScanner资源
scanner3.close();
}
}
6.在代码编辑区空白处单击右键,选择“Run As”-->“Java Application”,执行代码。
二、PageFilter
1.在Hbase项目com.hbase.filter包下,新建PageFilterExample类
2.创建程序入口main方法,代码如下:
//页过滤
//通过设置pagesize可以设置返回每一页的page大小
//客户端需要记录上一次返回的row的Key值
package com.hbase.filter hbaseTest;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.PageFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class PageFilterExample {
public static void main(String[] args) throws IOException {
//配置文件设置
//创建用于客户端的配置类实例
Configuration config = HBaseConfiguration.create();
//设置连接Zookeeper的地址
//hbase客户端连接的是Zookeeper
config.set("hbase.zookeeper.quorum", "QT-H-0038");
String tableName = "testTable";
String cfName = "colfam1";
//因为hbase的row是字典序列排列的,因此上一次的lastrow需要添加额外的0(0x00)表示新的开始。
final byte[] POSTFIX = new byte[] { 0x00 };
//获得要操作的表的对象
//“config”为配置文件,“tableName”为数据库中的表名
HTable table = new HTable(config, tableName);
//创建过滤器PageFilter,该过滤器表示按行分页,参数表示每个分页有3行记录
Filter filter = new PageFilter(3);
byte[] lastRow = null;
int totalRows = 0;
//为了演示效果,这里遍历所有符合条件的数据,需要循环输出
while (true) {
//初始化Scan实例,该实例用于查询符合条件的数据
Scan scan = new Scan();
//设置过滤器,将前面创建好的分页过滤器设置到Scan实例中
scan.setFilter(filter);
//设置遍历开始的位置,即表示开始的行键位置,如果是第一次循环(即第一页),则不进入该语句块
if(lastRow != null){
//注意这里添加了POSTFIX操作,否则陷入死循环
byte[] startRow = Bytes.add(lastRow,POSTFIX);
scan.setStartRow(startRow);
}
//执行查询,使用HTable实例执行扫描查询,并且将扫描结果输出,并且给行键遍历赋值
ResultScanner scanner = table.getScanner(scan);
int localRows = 0;
Result result;
//输出一页的结果
while((result = scanner.next()) != null){
System.out.println(localRows++ + ":" + result);
totalRows ++;
lastRow = result.getRow();
}
//释放ResultScanner资源
scanner.close();
if(localRows == 0) break;
}
System.out.println("total rows:" + totalRows);
//释放HTable资源
table.close();
}
}
3.在代码编辑区空白处单击右键,选择“Run As”-->“Java Application”,执行代码。