实验目的
了解基本聚类算法的基本原理,并掌握R语言中实现聚类算法的函数方法
实验原理
聚类就是将相似的事物聚集在一起,而将不相似的事物划分到不同的类别的过程,是数据分析之中十分重要的一种手段。在数据分析的术语之中,聚类和分类是两种技术。分类是指我们已经知道了事物的类别,需要从样品中学习分类的规则,是一种监督式学习;而聚类则是由我们来给定简单的规则,从而得到类别,是一种无监督学习。
在K均值算法中,质心是定义聚类原型(也就是机器学习获得的结果)的核心。在介绍算法实施的具体过程中,我们将演示质心的计算方法。而且你将看到除了第一次的质心是被指定的以外,此后的质心都是经由计算均值而获得的。
首先,选择K个初始质心(这K个质心并不要求来自于样本数据集),其中K是用户指定的参数,也就是所期望的簇的个数。每个数据点都被收归到距其最近之质心的分类中,而同一个质心所收归的点集为一个簇。然后,根据本次分类的结果,更新每个簇的质心。重复上述数据点分类与质心变更步骤,直到簇内数据点不再改变,或者等价地说,直到质心不再改变。
实验步骤
我们使用r语言中的数据集iris实现k-means聚类算法。
首先载入iris数据集并命名为iris1,移除Species类别属性:
> iris1 <- iris
> iris1$Species <- NULL
对iris1数据集调用函数kmeans(),并将结果存储在变量kmeans.result中,在命令外面加小括号可以直接查看函数调用结果
> (kmeans.result <- kmeans(iris1,3))
K-means clustering with 3 clusters of sizes 33, 21, 96
Cluster means:
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.175758 3.624242 1.472727 0.2727273
2 4.738095 2.904762 1.790476 0.3523810
3 6.314583 2.895833 4.973958 1.7031250
Clustering vector:
[1] 1 2 2 2 1 1 1 1 2 2 1 1 2 2 1 1 1 1 1 1 1 1 1 1 2 2 1 1 1 2 2 1 1 1 2 1 1 1 2 1 1 2 2 1 1 2 1
[48] 2 1 1 3 3 3 3 3 3 3 2 3 3 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2
[95] 3 3 3 3 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[142] 3 3 3 3 3 3 3 3 3
Within cluster sum of squares by cluster:
[1] 6.432121 17.669524 118.651875
(between_SS / total_SS = 79.0 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" "size" "iter" "ifault"
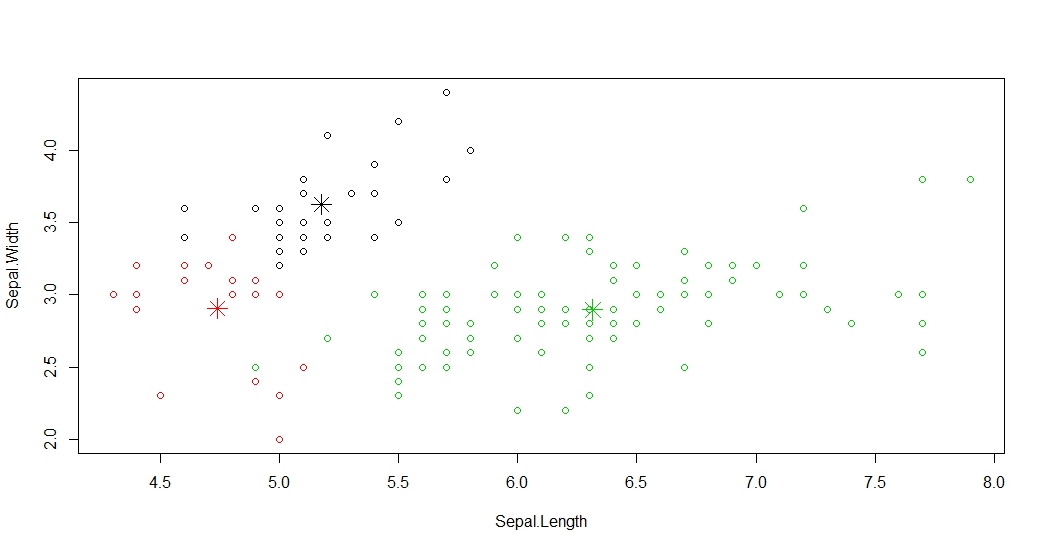
绘制散点图并标记所有的簇以及簇中心,需要注意的是数据集有四个维度但是绘图只使用前两个维度
> plot(iris1[c("Sepal.Length","Sepal.Width")],col=kmeans.result$cluster)
> points(kmeans.result$centers[,c("Sepal.Length","Sepal.Width")],col=1:3,pch=8,cex=2)