优秀员工离职原因分析与预测
实验目的
熟悉使用R语言进行大数据综合分析的方法
实验原理
R工具是一套完整的的数据处理计算和制图软件系统。其功能包括:数据存储和处理系统;数组运算工具(其向量、矩阵运算方面功能尤其强大);完整连贯的统计分析工具;优秀的的统计制图功能;简便而强大的的编程语言:可操纵数据的输入和输出以及可实现分支、循环等用户自定义功能。
实验背景
优秀且有经验的员工是所有企业都渴望得到的人才,正所谓“求贤若渴”。然而现实中存在的一个现象是:不少公司中大量优秀且有经验的员工过早的离开。
为什么我们最好、最有经验的员工那么早的离职?利用这个数据集,利用其中14999名员工工作年限、薪资、职位、部门、健康程度等有价值的信息,分析并得出优秀员工离职的主要可能的原因,并试着预测哪些有价值的员工将会离开。
实验步骤
- 熟悉R环境;
- 打开R云件环境;
- 在相应编程环境中修改和运行代码;
- 查看结果。
实验一:数据读取
从kaggle下载数据:地址
导入数据,加载分析包,如提示包不存在可以用install.packages("包名")的方式安装
library('dplyr')
library('corrplot')
library('rpart')
library('partykit')
library('grid')
library('caret')
library('readr')
library('ggplot2')
library('gmodels')
library('pROC')
HR<-read.csv('HR_comma_sep.csv',stringsAsFactors=F)
实验二:数据探索
查看数据结构:
str(HR)
'data.frame': 14999 obs. of 10 variables:
$ satisfaction_level : num 0.38 0.8 0.11 0.72 0.37 0.41 0.1 0.92 0.89 0.42 ...
$ last_evaluation : num 0.53 0.86 0.88 0.87 0.52 0.5 0.77 0.85 1 0.53 ...
$ number_project : int 2 5 7 5 2 2 6 5 5 2 ...
$ average_montly_hours : int 157 262 272 223 159 153 247 259 224 142 ...
$ time_spend_company : int 3 6 4 5 3 3 4 5 5 3 ...
$ Work_accident : int 0 0 0 0 0 0 0 0 0 0 ...
$ left : int 1 1 1 1 1 1 1 1 1 1 ...
$ promotion_last_5years: int 0 0 0 0 0 0 0 0 0 0 ...
$ sales : chr "sales" "sales" "sales" "sales" ...
$ salary : chr "low" "medium" "medium" "low"
• satisfaction_level : 满意度 • last_evaluation : 绩效评估 • number_project : 完成项目数 • average_montly_hours : 平均月度工作时间 • time_spend_company : 服务年限 • Work_accident : 是否有工伤 • left : 是否离职 • promotion_last_5years: 过去5年是否有升职 • sales : 工作部门 • salary:薪资水平
实验三:数据预处理
变量名称太长,我们将这些名称简化以下:
#将变量重命名:
HR<-rename(HR,satisfaction=satisfaction_level,evaluation=last_evaluation,project=number_project,avghours=average_montly_hours,timespend=time_spend_company,accident=Work_accident,promotion=promotion_last_5years,dept=sales)
查看有没有缺失值:
sum(is.na(HR))
[1] 0
发现没有缺失值。 将salary中的字符转换成数字,且将low记为1,medium记为2,high记为3
HR$salary[HR$salary=="low"]<-"1"
HR$salary[HR$salary=="medium"]<-"2"
HR$salary[HR$salary=="high"]<-"3"
HR$salary <- as.numeric(HR$salary)
实验四:分析建模
查看相关性:
HR2<-HR[-9]#先将字符型的部门变量减去#
corrplot.mixed(cor(HR2))
corrplot(cor(HR2),type="upper",method = "circle",tl.pos = "tl",tl.offset = 1,tl.srt = 0)
corrplot(cor(HR2),add=T,type="lower",method = "number",col="red",diag=F, tl.pos ="n",cl.pos ="n")
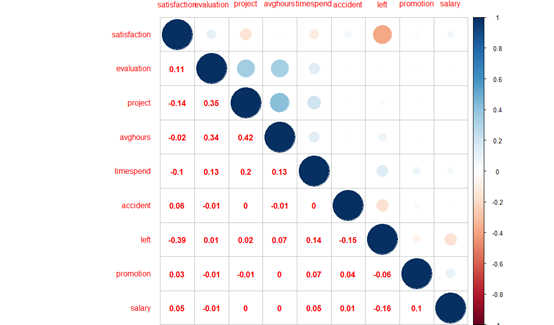
从图中可以看到,与离职相关的因素依次是满意度(-0.39)薪资(-0.16),工伤(-0.15),工作年限(0.14),工作时间(0.07),升职(-0.06)完成项目(0.02),绩效(0.01)。
满意度(satisfaction)与离职率的关系
HR$left<-as.factor(HR$left) #转换为factor类型
ggplot(HR,aes(x=satisfaction,fill=left ))+geom_histogram(binwidth =0.02)+labs(title="满意度与离职率的关系")
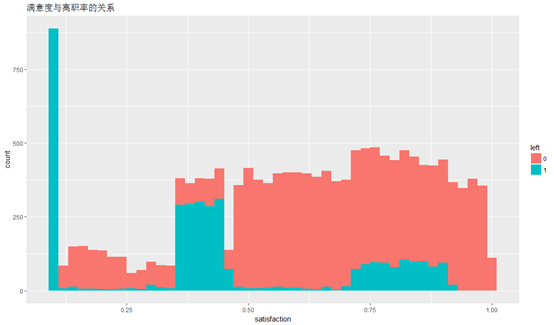
从图中可以看出,大部分离职人员满意度都在0.1以下,满意度在0.3-0.5之间的离职人数次之,满意度在0.7-0.9的离职人员最少。
薪资(salary)与离职率的关系:
ggplot(HR,aes(x=salary,y=..count..,fill=left ))+geom_bar(stat = "count",position = "stack")+labs(title="薪资与离职率的关系")+geom_text(stat="count",aes(label=..count..),position=position_stack(vjust=0.3))
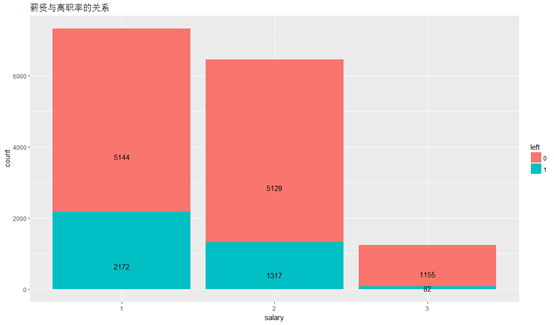
收入不到位在离职原因中也占很大比例,图中明显低收入员工离职率更高,差不多占三分之一,而反观高收入员工,离职人数少的可怜。
工伤(accident)与离职率的关系:
ggplot(HR,aes(x=accident,y=..count..,fill=left ))+geom_bar(stat = "count",position = "stack")+labs(title="工伤与离职率的关系")+geom_text(stat="count",aes(label=..count..),position=position_stack(vjust=0.3))
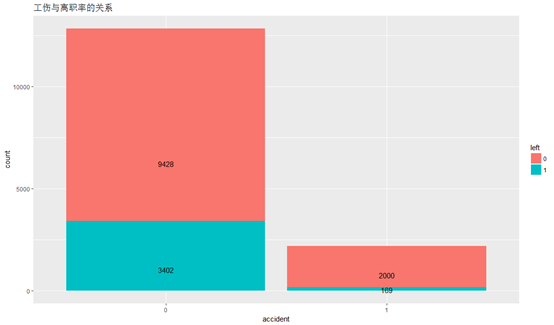
从图中可以看到,工伤虽然是导致离职的一个因素,但并不是主因。
工作年限(timespend)与离职率的关系:
ggplot(HR,aes(x=timespend,y=..count..,fill=left ))+geom_bar(stat = "count",position = "stack")+labs(title="工作年限与离职率的关系")+geom_text(stat="count",aes(label=..count..),position=position_stack(vjust=0.3))+scale_x_continuous(expand=c(0,0),breaks = c(1,2,3,4,5,6,7,8,9,10),labels = c(1,2,3,4,5,6,7,8,9,10))
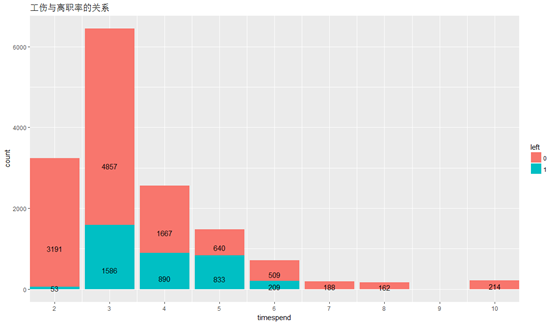
从图中可以看到工作3-5年是离职的高发期,巧合的是很多公司招聘的时候也都要求3-5年的工作经验。
月均工作时间(vghours)与离职率的关系:
ggplot(HR,aes(x=avghours,colour=left ))+geom_line(stat="bin",binwidth=5)+labs(title="月均工作时间与离职率的关系")
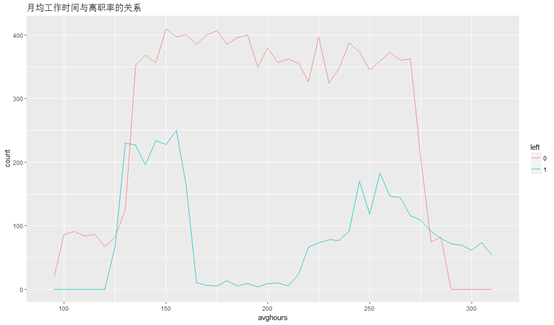
构建离职原因模型
数据分割
set.seed(0001)
train <- createDataPartition(HR$left, p=0.75, list=FALSE) #每次分割的结果可能不同,导致后面步骤的数据可能不同
hr_good_train <- HR[train, ]
hr_good_test <- HR[-train, ]
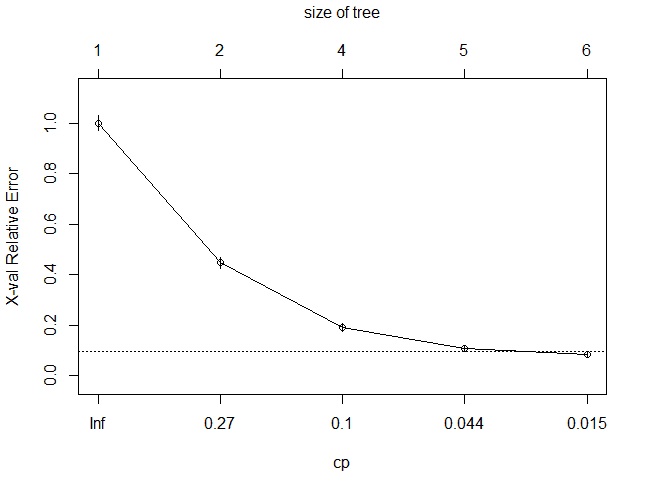
决策树
dtree <- rpart(left~., hr_good_train, method="class",parms=list(split="information"))
dtree$cptable
CP nsplit rel error xerror xstd
1 0.55209743 0 1.00000000 1.00000000 0.02950911
2 0.12855210 1 0.44790257 0.44790257 0.02256805
3 0.08254398 3 0.19079838 0.19079838 0.01551204
4 0.02300406 4 0.10825440 0.10825440 0.01186737
5 0.01000000 5 0.08525034 0.08525034 0.01057607
plotcp(dtree)
实验五:模型评价与优化
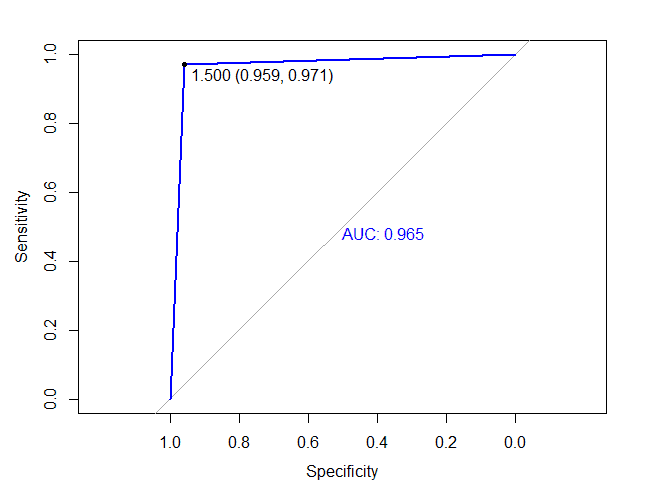
绘制ROC/AUC曲线
dtree.pruned <- prune(dtree, cp=0.01)
dtree.pruned.pred <- predict(dtree.pruned, hr_good_test, type="class")
roc(as.numeric(hr_good_test$left),as.numeric(dtree.pruned.pred), plot=TRUE, print.thres=TRUE, print.auc=TRUE,col="blue")
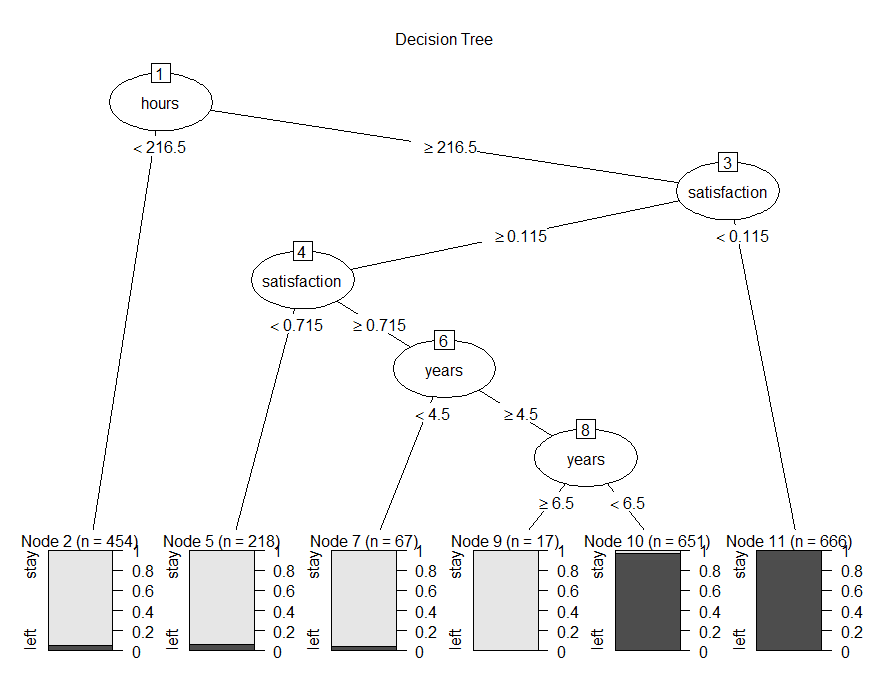
实验六:可视化输出
plot(as.party(dtree.pruned),main="Decision Tree")