实验目的
了解数据挖掘中需要数据预处理的几种情况,掌握R语言中数据预处理的几种方法
实验原理
在实际情况下,数据通常是不完整(缺少属性值或某些感兴趣的属性,或仅包含聚集数据)、含噪声(包含错误或存在偏离期望的离群值)、不一致的,这样的数据必须经过预处理,剔除其中的噪声,回复数据的完整性和一致性后才能使用数据挖掘技术进行分析。
本节教程主要展示了如何在R环境下处理缺失值和噪声。
实验步骤
1、缺失值处理
我们使用R语言mice包中的数据集nhanes2进行演示。
首先安装lattice、MASS、nnet、mice包并加载
> install.packages("lattice")
> install.packages("MASS")
> install.packages("nnet")
> install.packages("mice")
> library(lattice)
> library(MASS)
> library(nnet)
> library(mice)
加载nhanes数据集,其中nhanes数据集是mice包中一组含有缺失值、离散变量的小型数据集,该数据集含有25个观测,4个变量,分别为25个样本的年龄(age)、体质指数(bmi)、是否患有高血压(hyp)以及血清胆固醇含量(chl)
> data("nhanes2")
调用summary()函数查看数据集基本统计量
> summary(nhanes2)
age bmi hyp chl
20-39:12 Min. :20.40 no :13 Min. :113.0
40-59: 7 1st Qu.:22.65 yes : 4 1st Qu.:185.0
60-99: 6 Median :26.75 NA's: 8 Median :187.0
Mean :26.56 Mean :191.4
3rd Qu.:28.93 3rd Qu.:212.0
Max. :35.30 Max. :284.0
NA's :9 NA's :10
计算nhanes2数据集中缺失值数量
> sum(is.na(nhanes2))
[1] 27
计算nhanes2数据集中完整样本数量
> sum(complete.cases(nhanes2))
[1] 13
查看nhanes2数据集中缺失值的分布情况,如下表,其中表格内的1表示没有缺失值,0表示存在确实数据,并在每行和每列的末尾给出了缺失值的统计频数
> md.pattern(nhanes2)
age hyp bmi chl
13 1 1 1 1 0
1 1 1 0 1 1
3 1 1 1 0 1
1 1 0 0 1 2
7 1 0 0 0 3
0 8 9 10 27
在查看了数据集中的缺失值分布情况后,需要选择恰当的方法处理缺失值,具体的缺失值处理方法有直接删除法、随机插补法、均值法、回归模型插补法、热平台插补法、冷平台插补法、期望值最大法等等。
直接删除法是最为直接简单的、但前提是缺失数据的比例较小,且缺失数据是随机出现的,这样直接删除后对之后的分析影响不大。
随机插补法是指随机抽取某个样本代替缺失样本,下面展示如何在R语言中实现随机插补法,首先新建列表sub记录nhanes2数据集中第四列为缺失值的行数
> sub =which(is.na(nhanes2[,4]) == TRUE)
将第四列不为NA的数据存储在数据集dataTR中,将第四列为NA的数据存储在数据集dataTE中,并在非缺失值数据中简单抽样填补缺失值,可以看到填补缺失值后的数据集dataTE第四列已经不含有缺失值
> dataTR =nhanes2[-sub,]
> dataTE =nhanes2[sub,]
> dataTE[,4] =sample(dataTR[,4],length(dataTE[,4]),replace=T)
> dataTE
age bmi hyp chl
1 20-39 NA <NA> 118
4 60-99 NA <NA> 131
10 40-59 NA <NA> 187
11 20-39 NA <NA> 187
12 40-59 NA <NA> 187
15 20-39 29.6 no 187
16 20-39 NA <NA> 199
20 60-99 25.5 yes 187
21 20-39 NA <NA> 284
24 60-99 24.9 no 229
均值法通过计算缺失值所在变量所有非缺失值的均值来代替缺失值,该方法不会减少信息并且处理简单,但是当缺失值不是随机产生时会产生偏差,下面展示如何用均值法填补缺失值,首先新建列表sub记录nhanes2数据集中第四列为缺失值的行数
> sub =which(is.na(nhanes2[,4]) == TRUE)
将第四列不为NA的数据存储在数据集dataTR中,将第四列为NA的数据存储在数据集dataTE中,并在非缺失值数据中计算均值来填补数据集dataTE中的缺失值,可以看到填补缺失值后的数据集dataTE第四列已经不含有缺失值,并且缺失值全部用同样的值代替
> dataTR =nhanes2[-sub,]
> dataTE =nhanes2[sub,]
> dataTE[,4] = mean(dataTR[,4])
> dataTE
age bmi hyp chl
1 20-39 NA <NA> 191.4
4 60-99 NA <NA> 191.4
10 40-59 NA <NA> 191.4
11 20-39 NA <NA> 191.4
12 40-59 NA <NA> 191.4
15 20-39 29.6 no 191.4
16 20-39 NA <NA> 191.4
20 60-99 25.5 yes 191.4
21 20-39 NA <NA> 191.4
24 60-99 24.9 no 191.4
回归模型插补法是将需要插补的变量作为因变量,其它相关变量作为自变量,通过建立回归模型预测出因变量的值对缺失变量进行插补的缺失值插补方法,和上面两种方法相同,首先将第四列不为NA的数据存储在数据集dataTR中,将第四列为NA的数据存储在数据集dataTE中,利用dataTR中age为自变量,chl为因变量构建回归模型lm,按模型lm对dataTE中的缺失值进行预测并填补
> sub =which(is.na(nhanes2[,4]) == TRUE)
> dataTR =nhanes2[-sub,]
> dataTE =nhanes2[sub,]
> lm <- lm(chl~age,data=dataTR)
> dataTE[,4] = round(predict(lm,dataTE))
> dataTE
age bmi hyp chl
1 20-39 NA <NA> 169
4 60-99 NA <NA> 225
10 40-59 NA <NA> 203
11 20-39 NA <NA> 169
12 40-59 NA <NA> 203
15 20-39 29.6 no 169
16 20-39 NA <NA> 169
20 60-99 25.5 yes 225
21 20-39 NA <NA> 169
24 60-99 24.9 no 225
热平台插补法是在非缺失值所在的样本中找到一个与缺失值所在样本相似的样本,利用其观测值对缺失值进行填补,首先按照是否含有缺失值将数据集nhanes2分成存在缺失值的数据集accept和无缺失值的数据集donate:
> accept =nhanes2[which(apply(is.na(nhanes2),1,sum) !=0),]
> donate =nhanes2[which(apply(is.na(nhanes2),1,sum) ==0),]
热平台插补法就是对于acccept中的每个样本,在donate中找到与该样本相似的样本,用相似样本的对应值代替该样本的缺失值,比方说,对accept中的第二个样本,插补方法如下:
> accept[2,]
age bmi hyp chl
3 20-39 NA no 187
> sa =donate[which(donate[,1]==accept[2,1]&donate[,3]==accept[2,3]&donate[,4]==accept[2,4]),]
> sa
age bmi hyp chl
8 20-39 30.1 no 187
> accept[2,2]=sa[1,2]
> accept[2,]
age bmi hyp chl
3 20-39 30.1 no 187
实际操作中,当变量为连续时或当变量数量较多时,通常很难找到与需要插补样本完全相同的样本,此时可以将原数据集根据某些变量进行分层,在层中对缺失值进行均值插补,此方法即为冷平台插补法
如下例,首先根据变量hyp对数据集nhanes2进行分层
> level1 <- nhanes2[which(nhanes2[,3]=="yes"),]
> level1
age bmi hyp chl
14 40-59 28.7 yes 204
17 60-99 27.2 yes 284
18 40-59 26.3 yes 199
20 60-99 25.5 yes NA
接下来用层内均值法代替第四个样本中的缺失值
> level1[4,4] =mean(level1[1:3,4])
> level1
age bmi hyp chl
14 40-59 28.7 yes 204
17 60-99 27.2 yes 284
18 40-59 26.3 yes 199
20 60-99 25.5 yes 229
2、噪声数据处理
噪声是一个变量中的随机错误或偏差,包括错误值或偏离期望的孤立值点,在R语言中可以调用outliers包中的outlier函数寻找噪声数据,该函数通过寻找数据集中与其他观测值及均值差距最大的点作为异常值
下面随机生成100个标准正太随机数并找到其中的离群点,在散点图中标记
> y=rnorm(100)
> outlier(y)
[1] -2.888921
> which(y==outlier(y),arr.ind = TRUE)
[1] 32
> plot(y)
> points(32,outlier(y),pch=8)
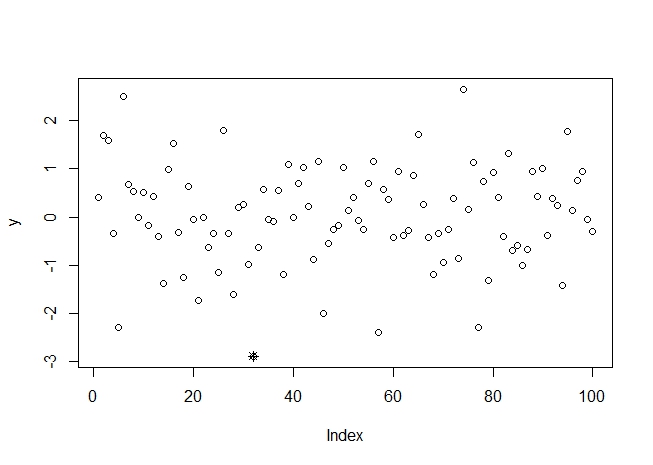
在进行噪声检查后,常用直接去除法、回归模型法、平均法等平滑数据,去除噪声数据