实验目的
了解决策树分类算法的基本原理,并掌握R语言中实现决策树算法的函数方法
实验原理
决策树(Decision Tree)是一种十分常用的分类算法,是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
实验步骤
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。下面我们在iris数据集上演示如何使用party包中的ctree()函数来建立一棵决策树。
调用决策树函数需要加载party包,因此首先安装party包并加载
> install.packages("party")
> library(party)
加载iris数据集,并生成采样数据,将iris数据集分为两部分,分别为训练数据集trainData和测试数据集testData
> data(iris)
> set.seed(1234)
> ind <- sample(2,nrow(iris),replace=TRUE,prob=c(0.7,0.3))
> testData <- iris[ind==2,]
> trainData <- iris[ind==1,]
调用ctree()函数,在训练集上建立决策树模型
> myFormular <- Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width
> iris_ctree <- ctree(myFormular,data=trainData)
查看决策树模型在训练数据集上的拟合效果
> table(predict(iris_ctree,trainData),trainData$Species)
setosa versicolor virginica
setosa 40 0 0
versicolor 0 37 3
virginica 0 1 31
由上表可以看出决策树模型在训练集上的拟合效果,其中错误分类的个数为4,分类正确率为96.43%
绘制生成的决策树
> plot(iris_ctree,type=”simple”)
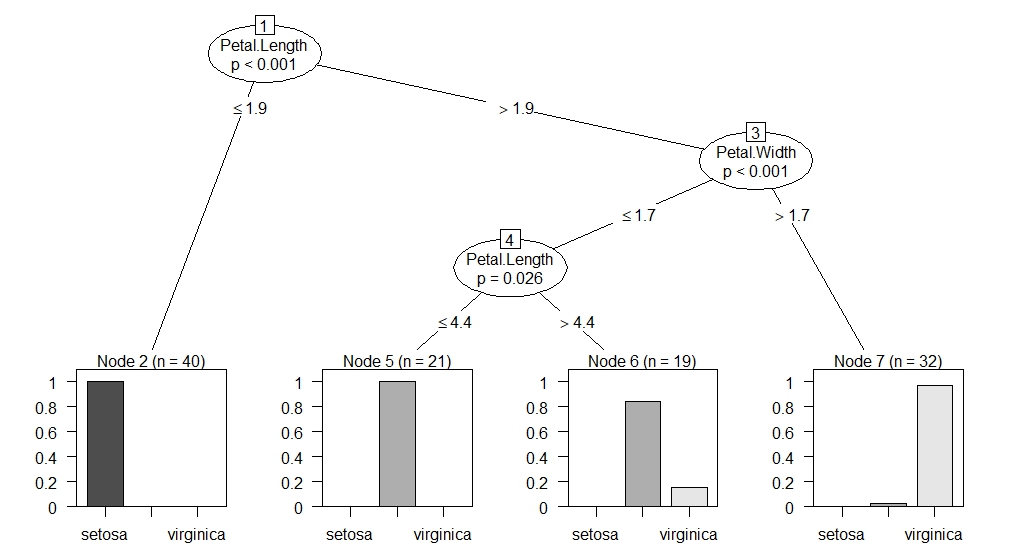 接下来查看决策树模型在测试集上的预测效果
接下来查看决策树模型在测试集上的预测效果
> testPred <- predict(iris_ctree,newdata=testData)
> table(testPred,testData$Species)
testPred setosa versicolor virginica
setosa 10 0 0
versicolor 0 12 2
virginica 0 0 14
由上表可以看出,决策树模型在测试集上错误分类个数为2,分类正确率为94.74%